Python中scrapy下載保存圖片的示例
在日常爬蟲練習中,我們爬取到的數據需要進行保存操作,在scrapy中我們可以使用ImagesPipeline這個類來進行相關操作,這個類是scrapy已經封裝好的了,我們直接拿來用即可。

在使用ImagesPipeline下載圖片數據時,我們需要對其中的三個管道類方法進行重寫,其中 — get_media_request 是對圖片地址發起請求
— file path 是返回圖片名稱
— item_completed 返回item,將其返回給下一個即將被執行的管道類

那具體代碼是什么樣的呢,首先我們需要在pipelines.py文件中,導入ImagesPipeline類,然后重寫上述所說的3個方法:
from scrapy.pipelines.images import ImagesPipelineimport scrapyimport os class ImgsPipLine(ImagesPipeline): def get_media_requests(self, item, info):yield scrapy.Request(url = item[’img_src’],meta={’item’:item}) #返回圖片名稱即可 def file_path(self, request, response=None, info=None):item = request.meta[’item’]print(’########’,item)filePath = item[’img_name’]return filePath def item_completed(self, results, item, info):return item
方法定義好后,我們需要在settings.py配置文件中進行設置,一個是指定圖片保存的位置IMAGES_STORE = ’D:ImgPro’,然后就是啟用“ImgsPipLine”管道,
ITEM_PIPELINES = { ’imgPro.pipelines.ImgsPipLine’: 300, #300代表優先級,數字越小優先級越高}
設置完成后,我們運行程序后就可以看到“D:ImgPro”下保存成功的圖片。
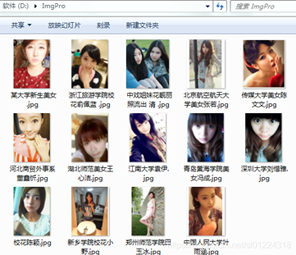
完整代碼如下:
spider文件代碼:
# -*- coding: utf-8 -*-import scrapyfrom imgPro.items import ImgproItem class ImgSpider(scrapy.Spider): name = ’img’ allowed_domains = [’www.521609.com’] start_urls = [’http://www.521609.com/daxuemeinv/’] def parse(self, response):#解析圖片地址和圖片名稱li_list = response.xpath(’//div[@class='index_img list_center']/ul/li’)for li in li_list: item = ImgproItem() item[’img_src’] = ’http://www.521609.com/’ + li.xpath(’./a[1]/img/@src’).extract_first() item[’img_name’] = li.xpath(’./a[1]/img/@alt’).extract_first() + ’.jpg’ # print(’***********’) # print(item) yield item
items.py文件
import scrapy class ImgproItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_src = scrapy.Field() img_name = scrapy.Field()
pipelines.py文件
from scrapy.pipelines.images import ImagesPipelineimport scrapyimport osfrom imgPro.settings import IMAGES_STORE as IMGS class ImgsPipLine(ImagesPipeline): def get_media_requests(self, item, info):yield scrapy.Request(url = item[’img_src’],meta={’item’:item}) #返回圖片名稱即可 def file_path(self, request, response=None, info=None):item = request.meta[’item’]print(’########’,item)filePath = item[’img_name’]return filePath def item_completed(self, results, item, info):return item
settings.py文件
import randomBOT_NAME = ’imgPro’ SPIDER_MODULES = [’imgPro.spiders’]NEWSPIDER_MODULE = ’imgPro.spiders’ IMAGES_STORE = ’D:ImgPro’ #文件保存路徑LOG_LEVEL = 'WARNING'ROBOTSTXT_OBEY = False#設置user-agentUSER_AGENTS_LIST = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1','Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5','Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3','Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3','Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24' ]USER_AGENT = random.choice(USER_AGENTS_LIST)DEFAULT_REQUEST_HEADERS = { ’Accept’: ’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ’Accept-Language’: ’en’, # ’User-Agent’:'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', ’User-Agent’:USER_AGENT} #啟動pipeline管道ITEM_PIPELINES = { ’imgPro.pipelines.ImgsPipLine’: 300,}
以上即是使用ImagesPipeline下載保存圖片的方法,今天突生一個疑惑,爬蟲爬的好,真的是牢飯吃的飽嗎?還請各位大佬解答!更多相關Python scrapy下載保存內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備