Python機(jī)器學(xué)習(xí)之Kmeans基礎(chǔ)算法
k-means算法是一種聚類算法,所謂聚類,即根據(jù)相似性原則,將具有較高相似度的數(shù)據(jù)對象劃分至同一類簇,將具有較高相異度的數(shù)據(jù)對象劃分至不同類簇。聚類與分類最大的區(qū)別在于,聚類過程為無監(jiān)督過程,即待處理數(shù)據(jù)對象沒有任何先驗(yàn)知識,而分類過程為有監(jiān)督過程,即存在有先驗(yàn)知識的訓(xùn)練數(shù)據(jù)集。
二、算法過程K-means中心思想:事先確定常數(shù)K,常數(shù)K意味著最終的聚類(或者叫簇)類別數(shù),首先隨機(jī)選定初始點(diǎn)為質(zhì)心,并通過計(jì)算每一個樣本與質(zhì)心之間的相似度(這里為歐式距離),將樣本點(diǎn)歸到最相似的類中,接著,重新計(jì)算每個類的質(zhì)心(即為類中心),重復(fù)這樣的過程,直到質(zhì)心不再改變,最終就確定了每個樣本所屬的類別以及每個類的質(zhì)心。由于每次都要計(jì)算所有的樣本與每一個質(zhì)心之間的相似度,故在大規(guī)模的數(shù)據(jù)集上,K-Means算法的收斂速度比較慢。
1.聚類算法:
是一種典型的無監(jiān)督學(xué)習(xí)算法,主要用于將相似的樣本自動歸到一個類別中。聚類算法與分類算法最大的區(qū)別是:聚類算法是無監(jiān)督的學(xué)習(xí)算法,而分類算法屬于監(jiān)督的學(xué)習(xí)算法,分類是知道結(jié)果的。在聚類算法中根據(jù)樣本之間的相似性,將樣本劃分到不同的類別中,對于不同的相似度計(jì)算方法,會得到不同的聚類結(jié)果,常用的相似度計(jì)算方法有歐式距離法。
2.聚類:
物理或抽象對象的集合分成由類似的對象組成的多個類的過程被稱為聚類。由聚類所生成的簇是一組數(shù)據(jù)對象的集合,這些對象與同一個簇中的對象彼此相似,與其他簇中的對象相異。
3.簇:
本算法中可以理解為,把數(shù)據(jù)集聚類成 k 類,即 k 個簇。
4.質(zhì)心:
指各個類別的中心位置,即簇中心。
5.距離公式:
常用的有:歐幾里得距離(歐氏距離)、曼哈頓距離、閔可夫斯基距離等。
三、文字步驟1.給定一個待處理的數(shù)據(jù)集
2.選擇簇的個數(shù)k(kmeans算法傳遞超參數(shù)的時候,只需設(shè)置最大的K值)
3.任意產(chǎn)生k個簇,生成K個簇的中心,記 K 個簇的中心分別為 c 1 , c 2 , . . . , c k c1,c2,...,ck c1,c2,...,ck;每個簇的樣本數(shù)量為 N 1 , N 2 , . . . , N 3 N1,N2,...,N3 N1,N2,...,N3。
4.通過歐幾里得距離公式計(jì)算各點(diǎn)到各質(zhì)心的距離,把每個點(diǎn)劃分給與其距離最近的質(zhì)心,從而初步把數(shù)據(jù)集分為了 K 類點(diǎn)。
5.更新質(zhì)心:通過下面的公式來更新每個質(zhì)心。就是,新的質(zhì)心的值等于當(dāng)前該質(zhì)心所屬簇的所有點(diǎn)的平均值。 c j = 1 N j ∑ i = 1 N j x i , y i c_{j}=frac{1}{N_{j}}sum_{i=1}^{N{j}}x_{i},y_{i} cj=Nj1i=1∑Njxi,yi
6.重復(fù)以上步驟直到滿足收斂要求。(通常就是確定的中心點(diǎn)不再改變。)
四、圖形展示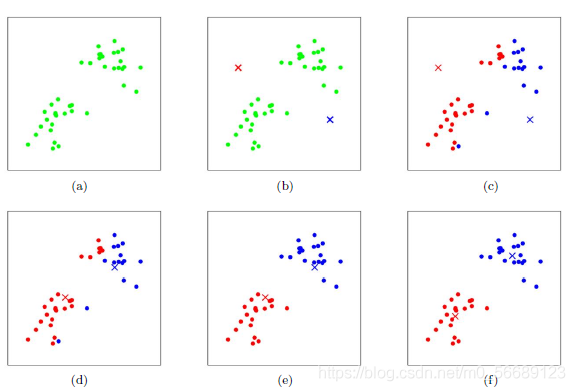
按照上述步驟我們可以更好地理解分類過程;
五、代碼實(shí)現(xiàn)x 軸數(shù)據(jù)],[存儲 y 軸數(shù)據(jù)]]for i in range(m): if i < m/3: data[0].append(uniform(1,5))#隨機(jī)設(shè)定data[1].append(uniform(1,5)) elif i < 2*m/3:data[0].append(uniform(6,10))data[1].append(uniform(1,5)) else:data[0].append(uniform(3,8))data[1].append(uniform(5,10))#將創(chuàng)建的數(shù)據(jù)集畫成散點(diǎn)圖plt.scatter(data[0],data[1])plt.xlim(0,11)plt.ylim(0,11)plt.show()#定義歐幾里得距離def distEuclid(x1,y1,x2,y2): d = sqrt((x1-x2)**2+(y1-y2)**2) return dcent0 = [uniform(2,9),uniform(2,9)] #定義 K=3 個質(zhì)心,隨機(jī)賦值cent1 = [uniform(2,9),uniform(2,9)] #[x,y]cent2 = [uniform(2,9),uniform(2,9)]mark = [] #標(biāo)記列表dist = [[],[],[]]#各質(zhì)心到所有點(diǎn)的距離列表#核心for n in range(50): #計(jì)算各質(zhì)心到所有點(diǎn)的距離 for i in range(m):dist[0].append(distEuclid(cent0[0],cent0[1],data[0][i],data[1][i]))dist[1].append(distEuclid(cent1[0],cent1[1],data[0][i],data[1][i]))dist[2].append(distEuclid(cent2[0],cent2[1],data[0][i],data[1][i])) #對數(shù)據(jù)進(jìn)行整理 sum0_x = sum0_y = sum1_x = sum1_y = sum2_x = sum2_y = 0 number0 = number1 = number2 = 0 for i in range(m):if dist[0][i]<dist[1][i] and dist[0][i]<dist[2][i]: mark.append(0) sum0_x += data[0][i] sum0_y += data[1][i] number0 += 1elif dist[1][i]<dist[0][i] and dist[1][i]<dist[2][i]: mark.append(1) sum1_x += data[0][i] sum1_y += data[1][i] number1 += 1elif dist[2][i]<dist[0][i] and dist[2][i]<dist[1][i]: mark.append(2) sum2_x += data[0][i] sum2_y += data[1][i] number2 += 1#更新質(zhì)心 cent0 = [sum0_x/number0,sum0_y/number0] cent1 = [sum1_x/number1,sum1_y/number1] cent2 = [sum2_x/number2,sum2_y/number2]#畫圖for i in range(m): if mark[i] == 0:plt.scatter(data[0][i],data[1][i],color=’red’) if mark[i] == 1:plt.scatter(data[0][i],data[1][i],color=’blue’) if mark[i] == 2:plt.scatter(data[0][i],data[1][i],color=’green’) plt.scatter(cent0[0],cent0[1],marker=’*’,color=’red’)plt.scatter(cent1[0],cent1[1],marker=’*’,color=’blue’)plt.scatter(cent2[0],cent2[1],marker=’*’,color=’green’)plt.xlim(0,11)plt.ylim(0,11)plt.show()在這里插入代碼片
上述代碼數(shù)據(jù)選擇是隨機(jī)生成的,每次運(yùn)行結(jié)果是不同的,測試會發(fā)現(xiàn)出現(xiàn)分類不理想的效果。說明基礎(chǔ)算法存在很大的弊端,我們需要改進(jìn),本篇內(nèi)容為基礎(chǔ)不做改進(jìn)知識的說明。
幾種較好的分類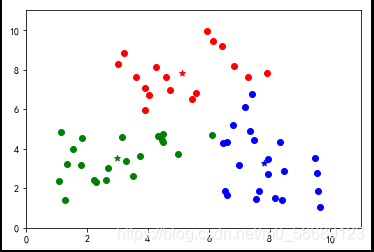
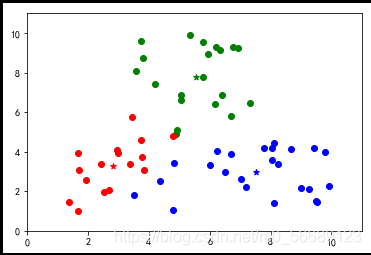
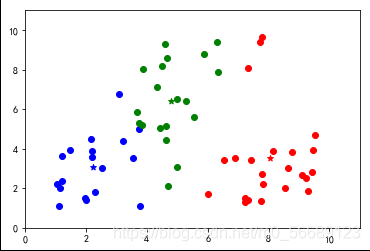
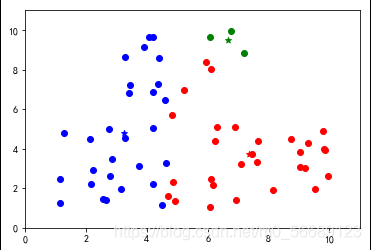
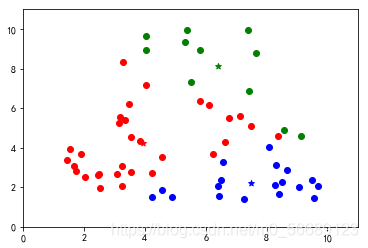
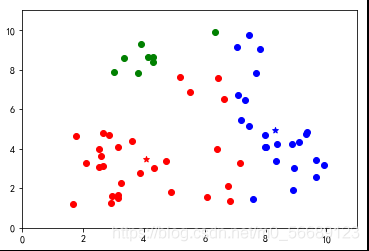
優(yōu)點(diǎn)
算法簡單易實(shí)現(xiàn);聚類效果依賴K值選定,
缺點(diǎn)
需要用戶事先指定類簇個數(shù);聚類結(jié)果對初始類簇中心的選取較為敏感;容易陷入局部最優(yōu); 只能發(fā)現(xiàn)球形類簇;
到此這篇關(guān)于Python機(jī)器學(xué)習(xí)之Kmeans基礎(chǔ)算法的文章就介紹到這了,更多相關(guān)Python Kmeans基礎(chǔ)算法內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 利用CSS3新特性創(chuàng)建透明邊框三角2. html清除浮動的6種方法示例3. CSS3實(shí)例分享之多重背景的實(shí)現(xiàn)(Multiple backgrounds)4. vue實(shí)現(xiàn)將自己網(wǎng)站(h5鏈接)分享到微信中形成小卡片的超詳細(xì)教程5. CSS代碼檢查工具stylelint的使用方法詳解6. 使用css實(shí)現(xiàn)全兼容tooltip提示框7. 詳解CSS偽元素的妙用單標(biāo)簽之美8. JavaScript數(shù)據(jù)類型對函數(shù)式編程的影響示例解析9. div的offsetLeft與style.left區(qū)別10. 不要在HTML中濫用div
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備