Python模擬登入的N種方式(建議收藏)
這段時間在研究如何破解官網驗證碼,然后進行下一步的爬蟲操作,然而一個多星期過去了,編寫的代碼去識別驗證碼的效率還是很低,嘗試用了tesserorc庫和百度的API接口,都無濟于事,本以為追不上五月的小尾巴,突然想到我嘗試了這么多方法何不為一篇破坑博客呢。
現在很多官網都會給出相應的反扒措施,就拿這個登入來說,如果你不登入賬號那么你就只能獲取微量的信息,甚至獲取不了信息,這對我們爬蟲來說是非常不友好的,但是我們總不可能每次都需要手動登入吧,一次二次你能接受,大工程呢?既然學了python,而不為用腳本代碼幫你做這點事情呢?
圖為簡書登入模塊:
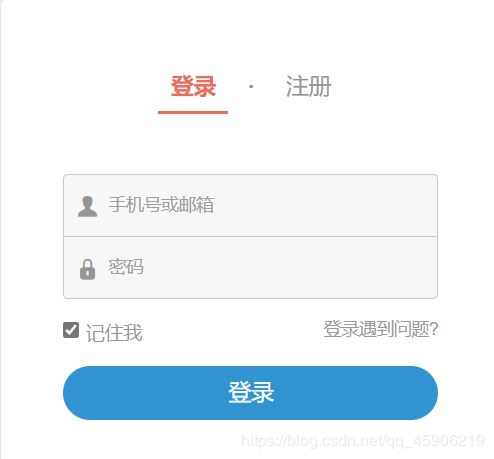
不同方式優缺點對比:
突然想到一種可能更簡單的方式,所以整理得三,不同情況參考不同用法!
如下:
方式 優點 缺點 requests的auth參數 極簡 出現的次數很少 requests的session會話 維持cookies一致 需要構造一定參數 selenium自動化 最強的模擬登入 安裝復雜,庫名太多
以上就是三大登入的優缺點,個人推薦使用session去嘗試模擬登入!
方式一: requests的auth參數:
這個是我無意在書上看到的。關于requests的高級用法中,提到了這點,這里就記錄一下,個人覺得這種方式只可能出現在某網站中,學了也挺好的,省的限制觀看次數,后續我也會更新如何破解vip視頻的思路,有需要的關注我。
使用類似場所:

用法很簡單,代碼如下:
# parasm: url : 網站# parasm: username: 用戶名# parasm: password : 密碼import requestsurl = ’********’r = requests.get(url, anth=(’username’, ’password’))print(r.text)
還是一句話,這種方式極大可能出現在某網站中,其他情況基本不可能出現,那么就得使用下面二種方式了。
方式一: requests高級用法擴展:
相信很多人看書都不看全的,很多細節都在書中呢,下面擴展幾種requests庫的高級用法,很好用的東西。
超時處理: 某網站服務器搭建在國外,加載巨慢。代碼可能拋出timeout : xxxx等情況,這個時候用它:
r = requests.get(url , timeout=30)
文件上傳: 假如某網站需要上傳文件,那么就使用它:
files = {’file’: open(’img.jpg’, ’rb’)}r = requests.get(url, files=files)print(r.text)
cookies設置: headers這個很多人都使用過吧,基本都是加一個代理頭就完事了,其實也可以設置其他的參數,然后使用post請求,就可以簡單的模擬登入一次了,用法如下:
這些字段一般都需要加上,常用的就是代理頭user-agent,這個必須設置:
headers = {’cookies’: ’瀏覽器復制’,’Host’: ’瀏覽器復制’, ’Referer’ ’瀏覽器復制’’User-Agent’: ’瀏覽器復制’}
方式二: requests的session會話使用:
會話是什么: 就好比你和朋友對接電話,你這頭是客戶端,朋友那頭是服務端,你們接通電話,這個通話記錄就代表一個會話,電話中,你可以通過聲音知道是你朋友,在服務器中,你請求成功一次,客戶端和服務端就維持了一個會話,這個會話能代表你的身份,那么這段時間在一個瀏覽器中,你進入網站就不需要在輸入賬號密碼了,直到你退出瀏覽器,那么會話截至,下次登入就需要再次輸入密碼了。
很好的是,Session能很好的幫助我們維持會話,從而達到cookies的一致性。區別于一半的請求requests,就可以達到get 和 post 共同的作用;
基本用法如下:
s = requests.Session()r = s.get(url)
那么我們使用會話從GitHub的模擬登入嘗試下:
首先我們需要登入一次,看看需要構建什么參數: 登入網站
在這個界面就開啟f12 , 不然看不了會話維持:
登入成功之后,如下圖,查看構造參數:
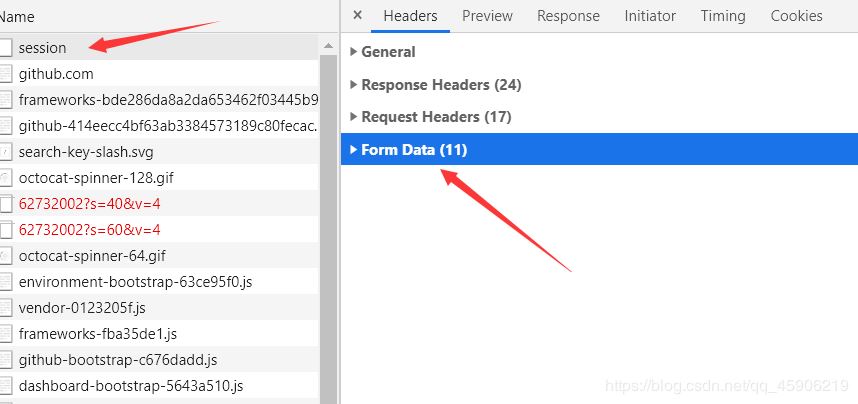
打開這個From Data 會發現,authenticity_token 這個字段,我們可能構造不了,這個時候,就得回到 登入界面了, 打開源代碼。F這個字段:

如圖: 只需要爬取這個頁面,獲得這個參數 那么就可以構造登入的所有參數了, 爬蟲代碼如下:
def token(self): # 獲得 authenticity_token 字段 方便下次模擬登入# login_url : 登入網址 r = self.session.get(self.login_url, headers=self.headers) if r.status_code == 200: r.encoding = r.apparent_encoding html = etree.HTML(r.text) html = etree.tostring(html) html = etree.fromstring(html) tk = html.xpath(’//*[@id='login']/form/input[1]/@value’) return tk
對于cookies的一致性,使用session 就已經搞定了這個問題,根據上圖的Name字段中的session ,我們可以找到會話網址: ‘https://github.com/session’
所以我們現在只需要構造一個函數去請求這個會話網址,就可以達到我們的要求了:
代碼如下, 這里我構造了一個class類,賬號密碼用自己,或者前面傳值過去,圖中的函數是二個爬蟲代碼,可以根據需求設計:
def login(self): # 模擬登入 post_date = { ’commit’: ’Sign in’, ’authenticity_token’: self.token(), ’ga_id’: ’1453216517.1584352055’, ’login’: self.email, ’password’: self.password } # 打印倉庫信息 r = self.session.post(self.post_url, data=post_date, headers=self.headers) if r.status_code == 200: self.get_info_1(r.text) # 打印個人信息和郵箱 r = self.session.get(self.logined_url, headers=self.headers) if r.status_code == 200: self.get_info_2(r.text)
會話登入到這里就結束了,主要是構造參數挺麻煩的,需要頁面里尋找,看到這里給個關注和贊啦。
方式三: selenium模擬登入:
如何下載selenium相關的插件,我就不做介紹了,篇幅有限
使用selenium 就是需要考慮到表單的切換,和定位元素等,其他都很簡單,這里用4399游戲網頁做一個實例: 網址
點擊登入:
彈出登入表單:
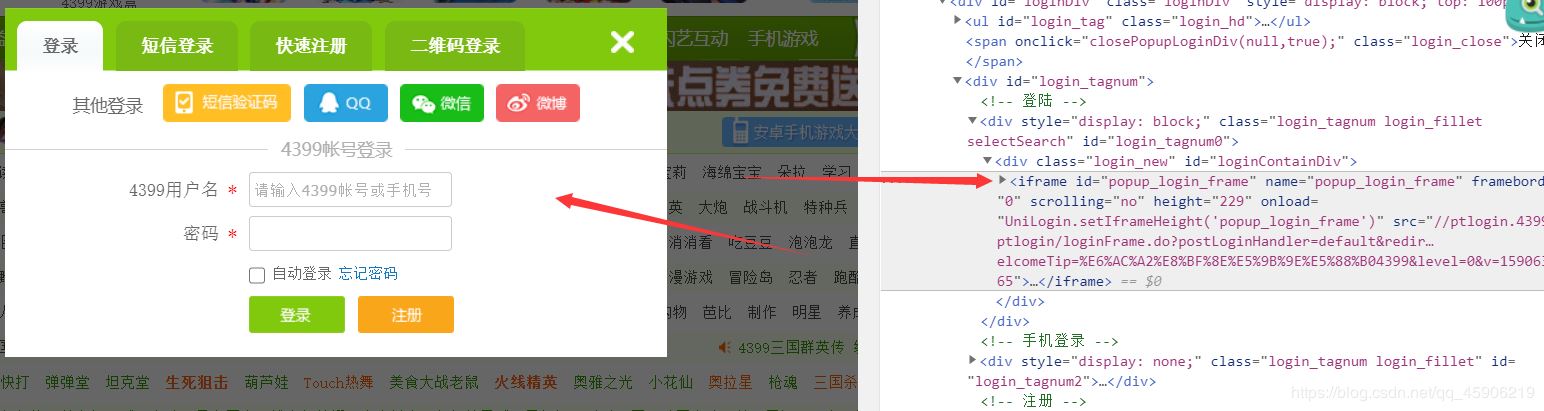
這里我們需要切換表單,不然輸入不了,怎么找到這個表單的,很簡單,整塊的高亮就行:
代碼如下:
from selenium import webdriver # 導入庫from selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome() # 聲明瀏覽器browser.implicitly_wait(30) # 隱性等待 在規定的時間內,最長等待S秒browser.get(’http://www.4399.com’) # 打開設置的網址# ID定位 或者其他的都行browser.find_element_by_id(’login_tologin’).click() # 點擊登入界面browser.switch_to.frame('popup_login_frame') # 進入表單中browser.find_element_by_css_selector(’#username’).clear()browser.find_element_by_id(’username’).send_keys(’賬號’)browser.find_element_by_id(’username’).send_keys(Keys.TAB)browser.find_element_by_id(’j-password’).send_keys(’密碼’)browser.find_element_by_id(’j-password’).send_keys(Keys.ENTER)
我給的例子沒有涉及到驗證碼,如果涉及到驗證碼,要不人工輸入,要么破解驗證碼,或者交給打碼平臺,最好的方式就是繞過驗證碼,這個我也在思考如何去實現。以上就是這周的知識總結,有幫助的話,就點個贊和關注吧!
到此這篇關于Python模擬登入的N種方式的文章就介紹到這了,更多相關Python 模擬登入內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備