python實(shí)現(xiàn)Scrapy爬取網(wǎng)易新聞
在命令行窗口下輸入scrapy startproject scrapytest, 如下
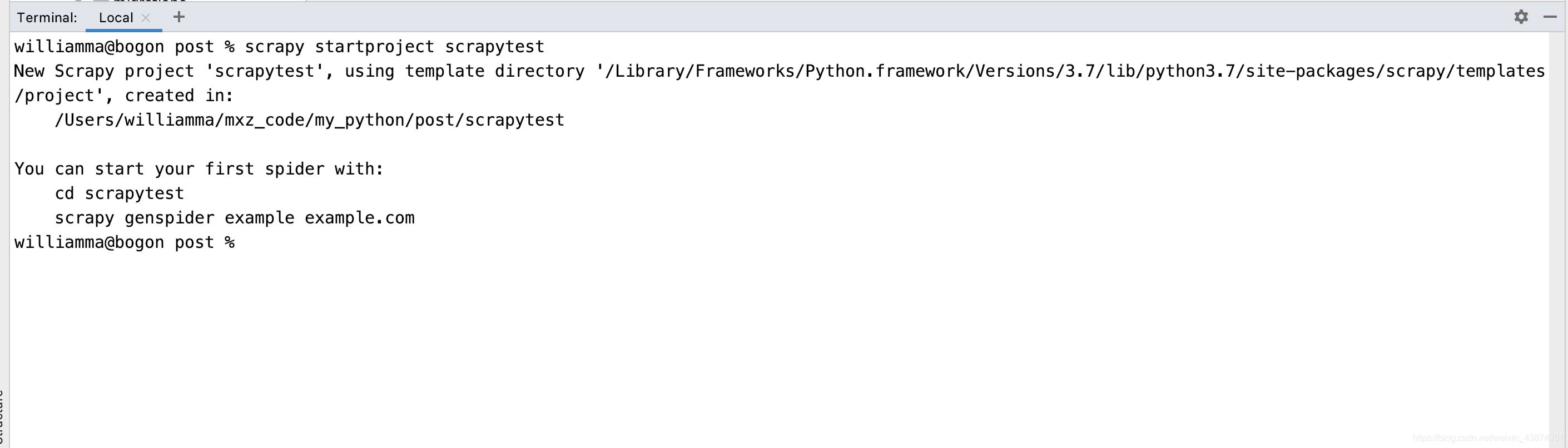
然后就自動(dòng)創(chuàng)建了相應(yīng)的文件,如下
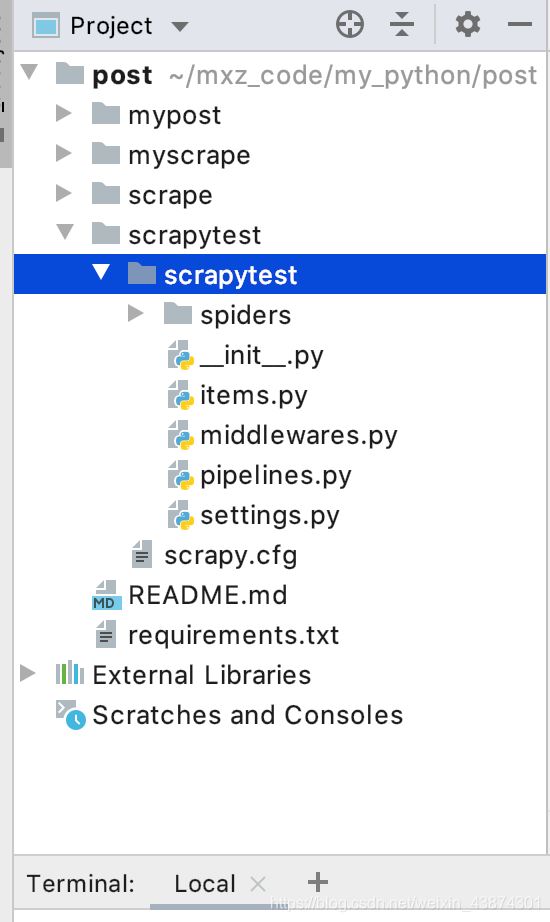
打開scrapy框架自動(dòng)創(chuàng)建的items.py文件,如下
# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
編寫里面的代碼,確定我要獲取的信息,比如新聞標(biāo)題,url,時(shí)間,來(lái)源,來(lái)源的url,新聞的內(nèi)容等
class ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() timestamp = scrapy.Field() category = scrapy.Field() content = scrapy.Field() url = scrapy.Field() pass3. 定義spider,創(chuàng)建一個(gè)爬蟲模板3.1 創(chuàng)建crawl爬蟲模板
在命令行窗口下面 創(chuàng)建一個(gè)crawl爬蟲模板(注意在文件的根目錄下面,指令檢查別輸入錯(cuò)誤,-t 表示使用后面的crawl模板),會(huì)在spider文件夾生成一個(gè)news163.py文件
scrapy genspider -t crawl codingce news.163.com
然后看一下這個(gè)‘crawl’模板和一般的模板有什么區(qū)別,多了鏈接提取器還有一些爬蟲規(guī)則,這樣就有利于我們做一些深度信息的爬取
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleclass CodingceSpider(CrawlSpider): name = ’codingce’ allowed_domains = [’163.com’] start_urls = [’http://news.163.com/’] rules = ( Rule(LinkExtractor(allow=r’Items/’), callback=’parse_item’, follow=True), ) def parse_item(self, response): item = {} #item[’domain_id’] = response.xpath(’//input[@id='sid']/@value’).get() #item[’name’] = response.xpath(’//div[@id='name']’).get() #item[’description’] = response.xpath(’//div[@id='description']’).get() return item3.2 補(bǔ)充知識(shí):selectors選擇器
支持xpath和css,xpath語(yǔ)法如下
/html/head/title/html/head/title/text()//td (深度提取的話就是兩個(gè)/)//div[@class=‘mine’]3.3. 分析網(wǎng)頁(yè)內(nèi)容
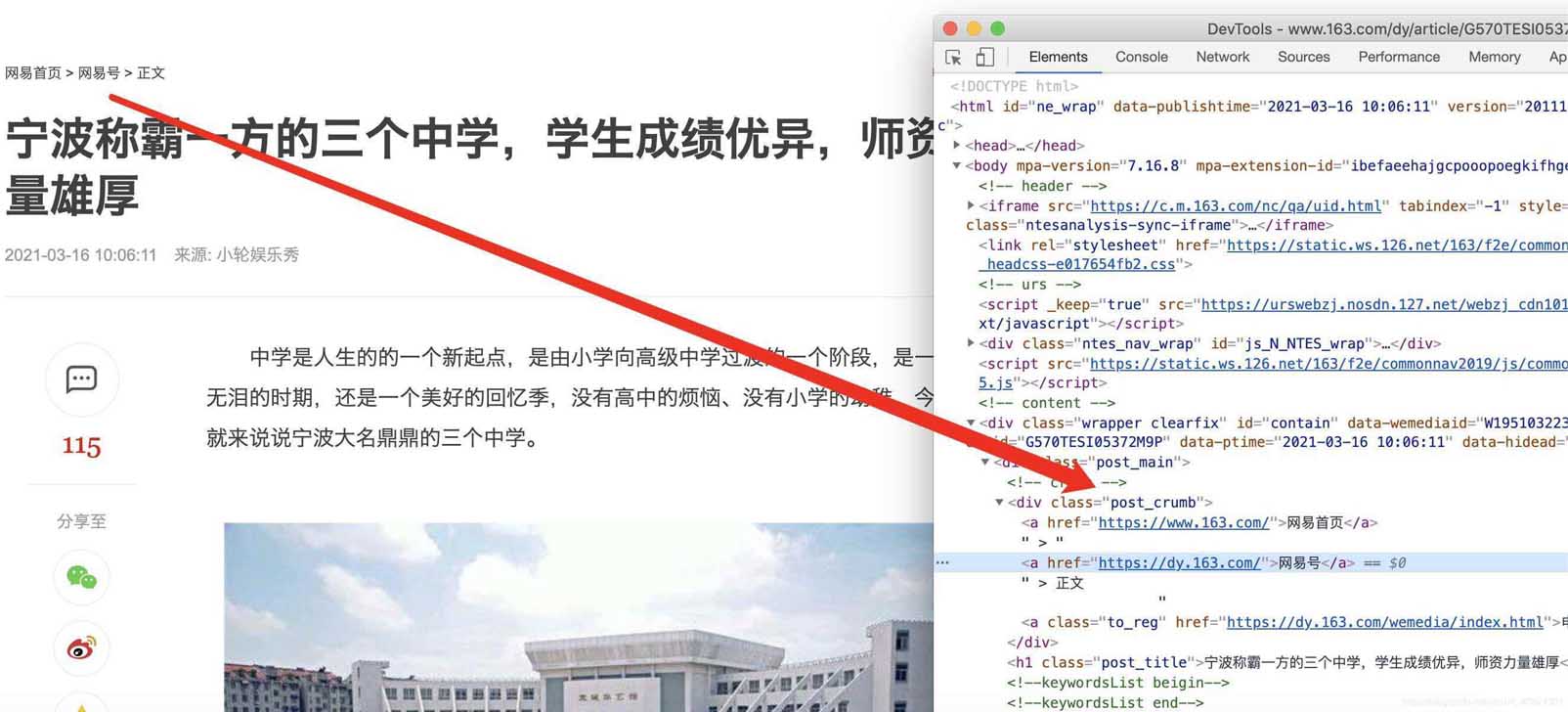
在谷歌chrome瀏覽器下,打在網(wǎng)頁(yè)新聞的網(wǎng)站,選擇查看源代碼,確認(rèn)我們可以獲取到itmes.py文件的內(nèi)容(其實(shí)那里面的要獲取的就是查看了網(wǎng)頁(yè)源代碼之后確定可以獲取的)
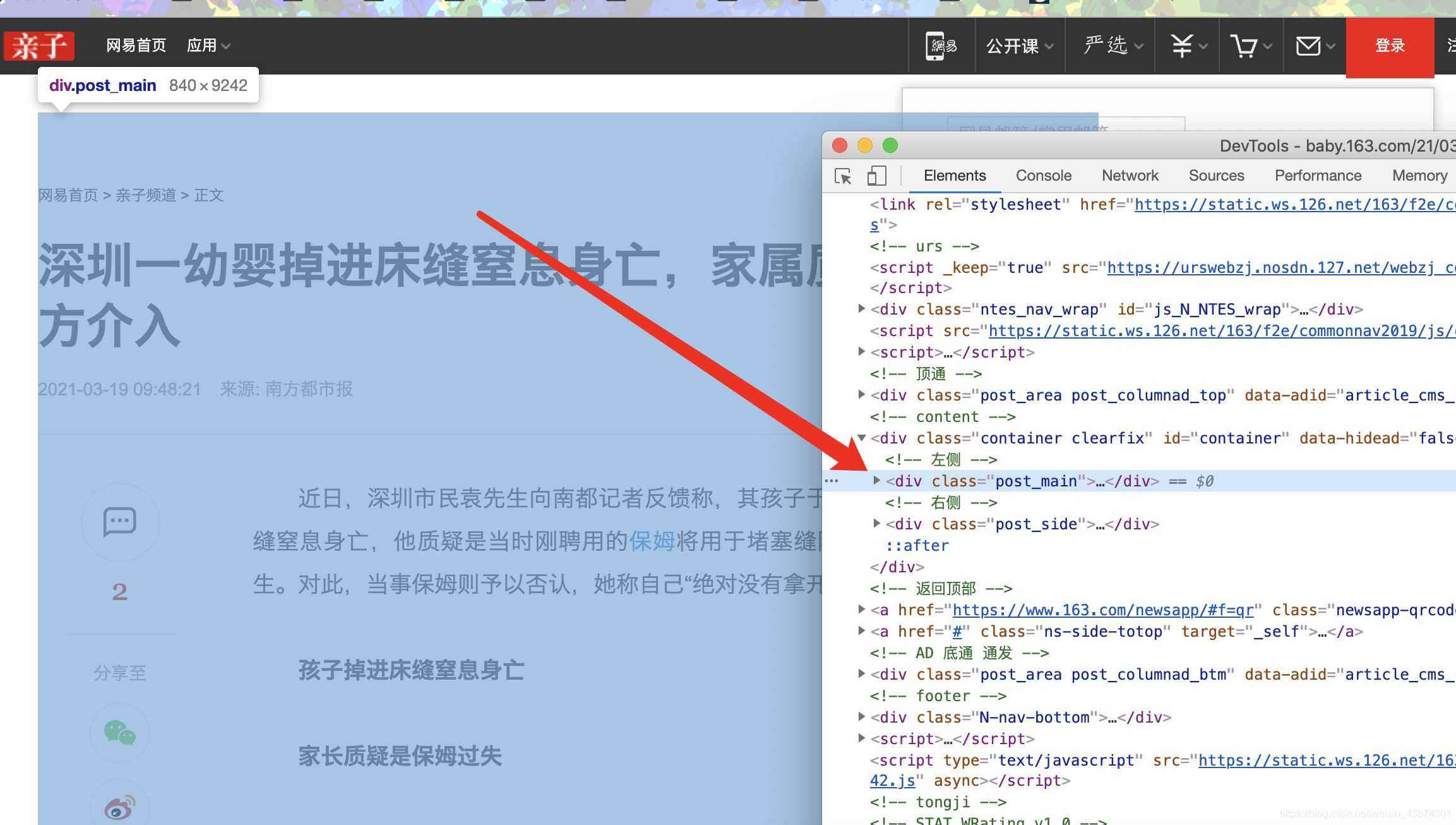
確認(rèn)標(biāo)題、時(shí)間、url、來(lái)源url和內(nèi)容可以通過(guò)檢查和標(biāo)簽對(duì)應(yīng)上,比如正文部分
主體
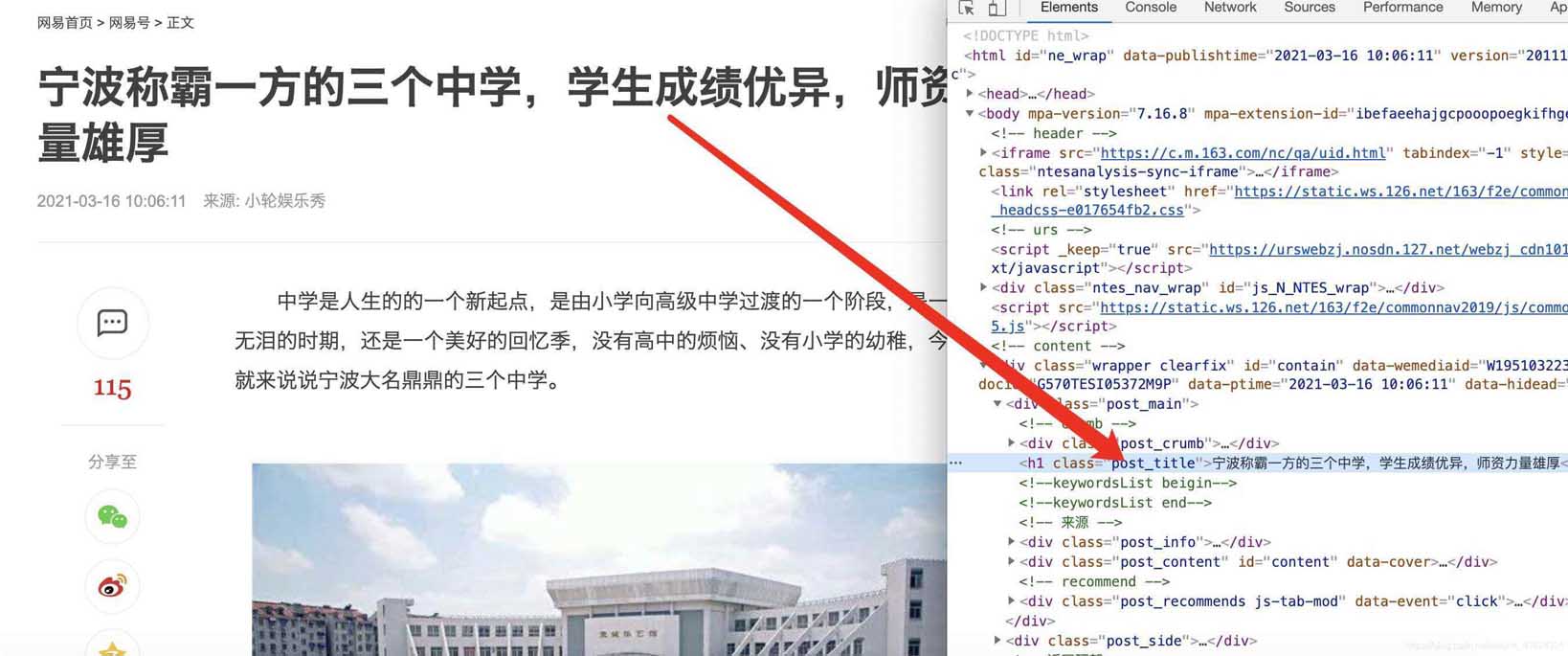
標(biāo)題
時(shí)間
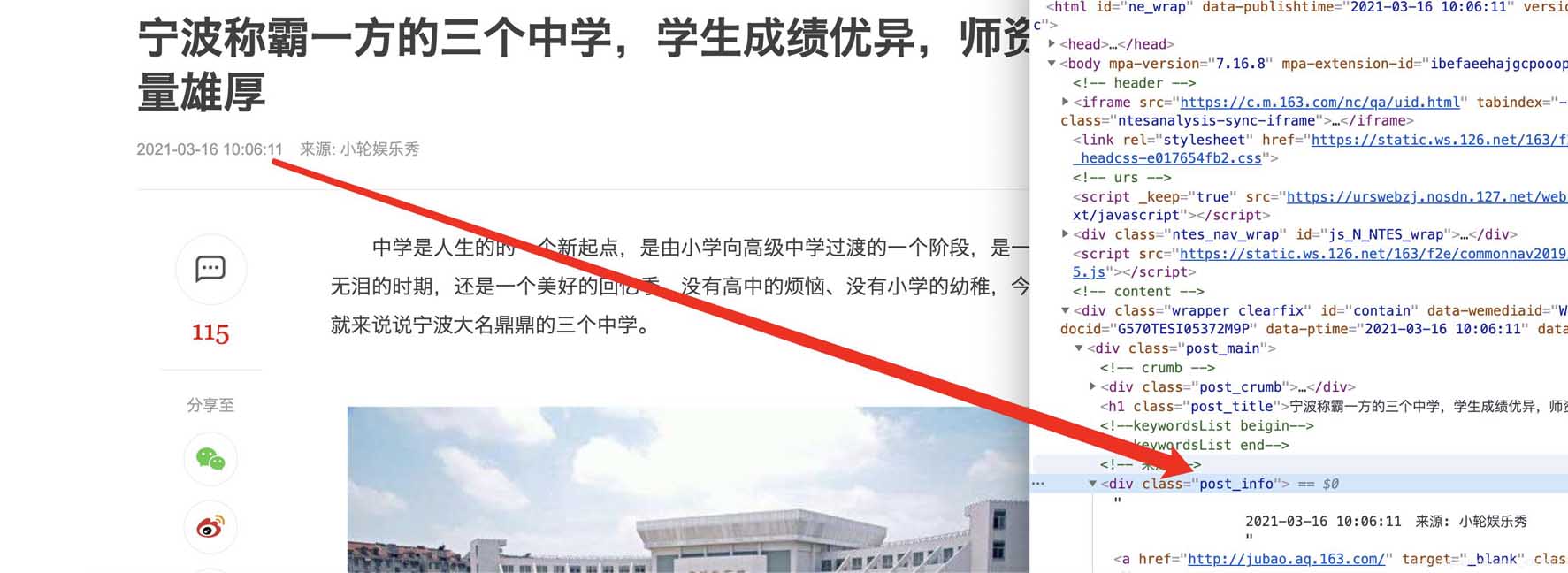
分類
打開創(chuàng)建的爬蟲模板,進(jìn)行代碼的編寫,除了導(dǎo)入系統(tǒng)自動(dòng)創(chuàng)建的三個(gè)庫(kù),我們還需要導(dǎo)入news.items(這里就涉及到了包的概念了,最開始說(shuō)的?init?.py文件存在說(shuō)明這個(gè)文件夾就是一個(gè)包可以直接導(dǎo)入,不需要安裝)
注意:使用的類ExampleSpider一定要繼承自CrawlSpider,因?yàn)樽铋_始我們創(chuàng)建的就是一個(gè)‘crawl’的爬蟲模板,對(duì)應(yīng)上
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom scrapytest.items import ScrapytestItemclass CodingceSpider(CrawlSpider): name = ’codingce’ allowed_domains = [’163.com’] start_urls = [’http://news.163.com/’] rules = ( Rule(LinkExtractor(allow=r’.*.163.com/d{2}/d{4}/d{2}/.*.html’), callback=’parse’, follow=True), ) def parse(self, response): item = {} content = ’<br>’.join(response.css(’.post_content p::text’).getall()) if len(content) < 100: return return item
Rule(LinkExtractor(allow=r’..163.com/d{2}/d{4}/d{2}/..html’), callback=‘parse’, follow=True), 其中第一個(gè)allow里面是書寫正則表達(dá)式的(也是我們核心要輸入的內(nèi)容),第二個(gè)是回調(diào)函數(shù),第三個(gè)表示是否允許深入
最終代碼
from datetime import datetimeimport reimport scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom scrapytest.items import ScrapytestItemclass CodingceSpider(CrawlSpider): name = ’codingce’ allowed_domains = [’163.com’] start_urls = [’http://news.163.com/’] rules = ( Rule(LinkExtractor(allow=r’.*.163.com/d{2}/d{4}/d{2}/.*.html’), callback=’parse’, follow=True), ) def parse(self, response): item = {} content = ’<br>’.join(response.css(’.post_content p::text’).getall()) if len(content) < 100: return title = response.css(’h1::text’).get() category = response.css(’.post_crumb a::text’).getall()[-1] print(category, '=======category') time_text = response.css(’.post_info::text’).get() timestamp_text = re.search(r’d{4}-d{2}-d{2} d{2}:d{2}:d{2}’, time_text).group() timestamp = datetime.fromisoformat(timestamp_text) print(title, '=========title') print(content, '===============content') print(timestamp, '==============timestamp') print(response.url) return item
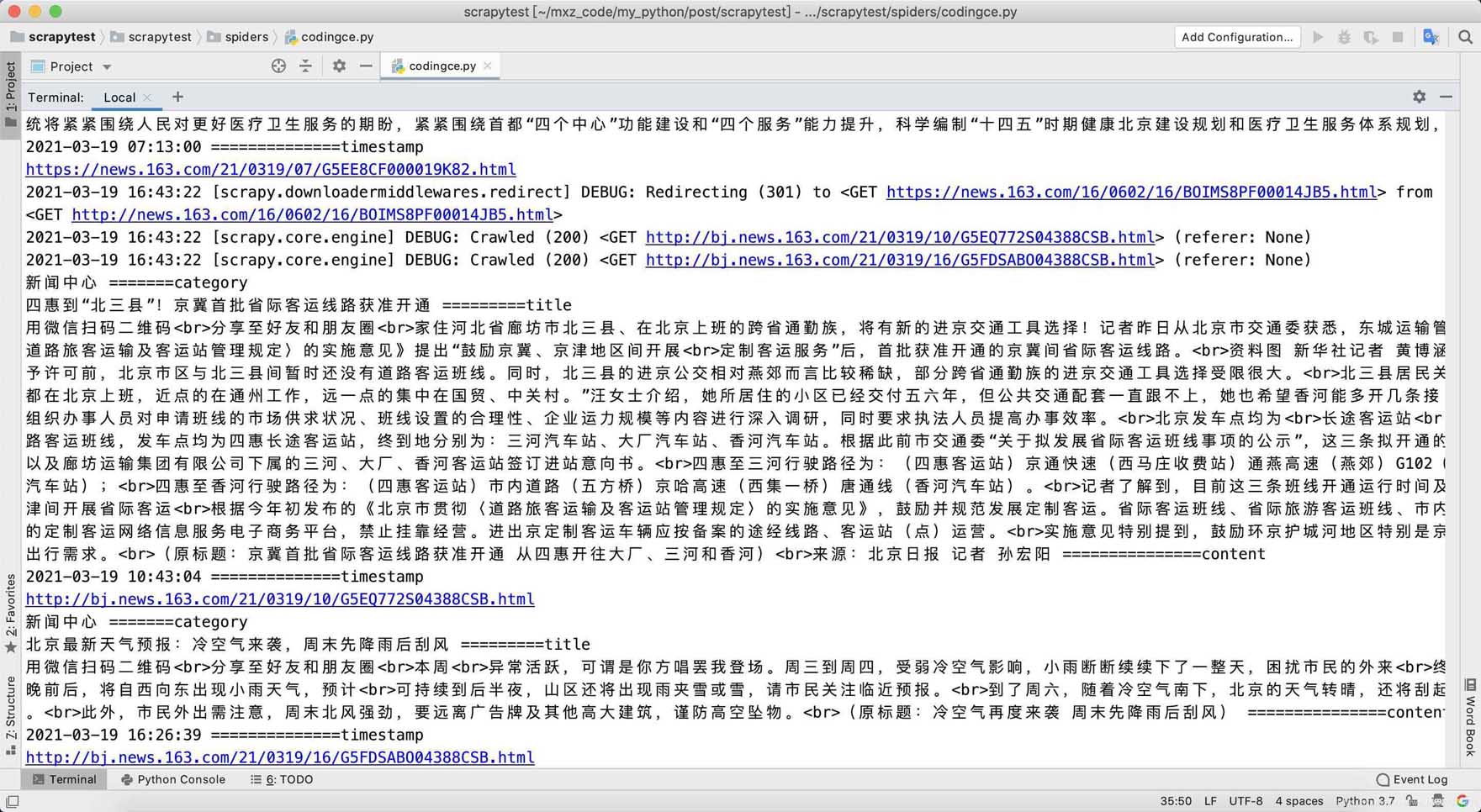
到此這篇關(guān)于python實(shí)現(xiàn)Scrapy爬取網(wǎng)易新聞的文章就介紹到這了,更多相關(guān)python Scrapy爬取網(wǎng)易新聞內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python GUI庫(kù)圖形界面開發(fā)之PyQt5動(dòng)態(tài)(可拖動(dòng)控件大小)布局控件QSplitter詳細(xì)使用方法與實(shí)例2. XML 非法字符(轉(zhuǎn)義字符)3. XML入門的常見問(wèn)題(三)4. ASP將數(shù)字轉(zhuǎn)中文數(shù)字(大寫金額)的函數(shù)5. CSS清除浮動(dòng)方法匯總6. vue跳轉(zhuǎn)頁(yè)面常用的幾種方法匯總7. 不要在HTML中濫用div8. ASP動(dòng)態(tài)include文件9. CSS3實(shí)例分享之多重背景的實(shí)現(xiàn)(Multiple backgrounds)10. js開發(fā)中的頁(yè)面、屏幕、瀏覽器的位置原理(高度寬度)說(shuō)明講解(附圖)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備