MySQL簡單主從方案暴露問題
從本篇文章開始我們將向讀者介紹mysql的各種服務集群的搭建方式。大致的討論思路是從最簡的MySQL主從方案開始介紹,通過這種方案的不足延伸出更復雜的集群方案,并介紹后者是如何針對這些不足進行改進的。
2、MySQL最簡單主從方案及工作原理我們講解的版本還是依據目前在生產環境上使用最多的version 5.6進行,其中一些特性在Version 5.7和最新的Version 8.0中有所改進,但這不影響讀者通過文章去理解構建MySQL集群的技術思路,甚至可以將這種機制延續到MariaDB。例如馬上要提到的MySQL自帶的日志復制機制(Replicaion機制)。
MySQL自帶的日志復制機制稱為MySQL-Replicaion。從MySQL很早的 Version 5.1版本就有Replicaion技術,發展到現有版本該技術已經非常成熟,通過它的支持技術人員可以做出多種MySQL集群結構。當然,后文我們還會介紹一些由第三方軟件/組件支持的MySQL集群方案。
2-1、MySQL-Replicaion基本工作原理
Replicaion機制從技術層面講,存在兩種基本角色:Master和Salve。Master節點負責在Replicaion機制中,向一個或者多個目標輸出數據,而Salve節點負責在Replicaion機制中接受Master節點傳來的數據。在實際業務環境下,Master節點和Salve節點還分別有另外一個名字:Write節點和Read節點——是的,利用Replicaion機制我們可以搭建以讀寫分離為目標的MySQL集群服務。但是為了保證讀者在閱讀文章內容時不會產生歧義,在本文(和后續文章)中我們都將使用Master節點和Salve節點這樣的稱呼。Replicaion機制依靠MySQL服務的二進制日志同步數據:
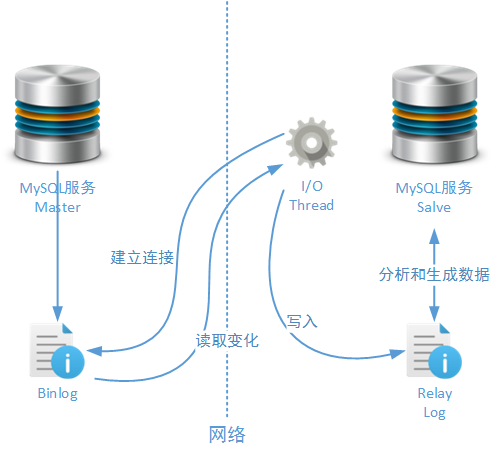
如上圖所示,Salve在啟動后會建立一個和Master節點的網絡連接,當Master節點的二進制日志發生變化后,一個或者多個MySQL Salve服務節點就會通過網絡接監聽到這些變化日志。接著Salve節點會首先在本地將這些變化寫入中繼日志文件(Relay Log),這樣做是為了盡量避免MySQL服務在出現異常時同步數據失敗,其原理和之前介紹過的InnoDB Log的工作原理相似。當中繼日志文件發生完成記錄后,MySQL Salve服務會將這些變化反映到對應的數據表中,完成一次數據同步過程。最后Salve會更新重做日志文件中的更新點(Position),并準備下一次Replicaion操作。
在這個過程中多個要素都可以進行配置,例如可以通過sync_binlog參數配置Master節點上數據操作次數和日志寫入次數配比關系、可以通過binlog_format參數配置日志數據的信息結構、可以通過sync_relay_log參數配置Salve節點上系統接收日志數據與寫入中繼日志文件次數的配比關系。這些參數和其它一些在示例中使用的參數會在本文后續小節進行介紹。
2-2、MySQL一主多從搭建方式
介紹完MySQL Replicaion機制的基本工作方式后,我們緊接著就來快速搭建由一個Master節點和一個Salve節點構成的MySQL集群。讀者可以從這個一主一從的MySQL集群方案擴展出任何一主多從的集群方案:
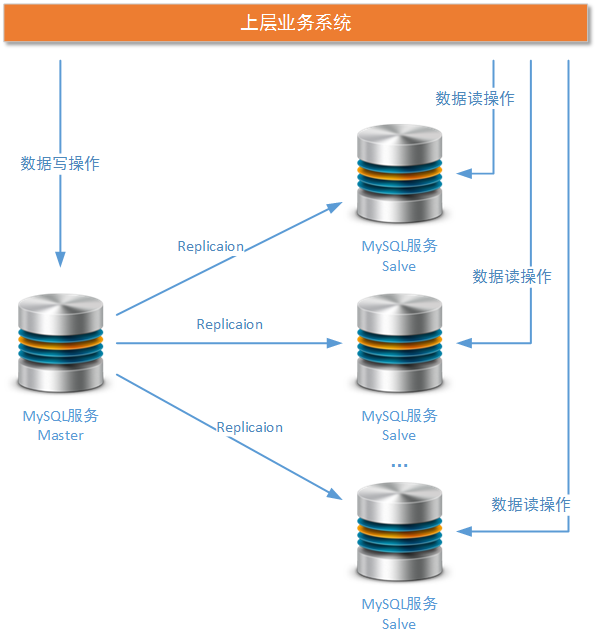
這個實例我們使用Version 5.6版本進行設置,當然version 5.7版本的安裝也是類似的。另外,在linux 操作系統上(Centos 5.6/5.7/6.X)安裝MySQL服務和進行基本設置的過程,由于篇幅和文章定位原因這里就不再進行贅述。我們將分別在如下ip的Linux操作安裝集群的Master節點和Salve節點:
MySQL Master服務:192.168.61.140
MySQL Salve服務:192.168.61.141
2-2-1、設置Master服務器
首先需要更改MySQL Master服務my.cnf主配置文件的信息,主要目的是開啟Master節點上的二進制日志功能(注意這里說的日志并不是InnoDB引擎日志)。
# my.cnf文件中沒有涉及Replicaion機制的配置信息,就不在這里列出了......# 開啟日志log_bin
# 以下這些參數會在后文進行說明
sync_binlog=1
binlog_format=mixed
binlog-do-db=qiang
binlog_checksum=CRC32
binlog_cache_size=2M
max_binlog_cache_size=1G
max_binlog_size=100M
# 必須為這個MySQL服務節點設置一個集群中唯一的 server id信息
server_id=140
......
在Master節點的設置中,有很多參數可以對日志的生成、存儲、傳輸過程進行控制。具體可以參見MySQL官網中的介紹:http://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html。這里我們主要對以上配置示例中出現的參數進行概要介紹:
sync_binlog:該參數可以設置為1到N的任何值。該參數表示MySQL服務在成功完成多少次不可分割的數據操作后(例如InnoDB引擎下的事務操作),才進行一次二進制日志文件的寫入操作。設置成1時,寫入日志文件的次數是最頻繁的,也會造成一定的I/O性能消耗,但同時這樣的設置值也是最安全的。
binlog_format:該參數可以有三種設置值:row、statement和mixed。row代表二進制日志中記錄數據表每一行經過寫操作后被修改的最終值。各個參與同步的Salve節點,也會參照這個最終值,將自己數據表上的數據進行修改;statement形式是在日志中記錄數據操作過程,而非最終的執行結果。各個參與同步的Salve節點會解析這個過程,并形成最終記錄;mixed設置值,是以上兩種記錄方式的混合體,MySQL服務會自動選擇當前運行狀態下最適合的日志記錄方式。
binlog-do-db:該參數用于設置MySQL Master節點上需要進行Replicaion操作的數據庫名稱。
binlog_checksum:該參數用于設置Master節點和Salve節點在進行日志文件數據同步時,所使用的日志數據校驗方式。這個參數是在version 5.6版本開始才支持的新配置功能,默認值就是CRC32。如果MySQL集群中有MySQL 節點使用的是version 5.5或更早的版本,請設置該參數的值為none。
binlog_cache_size:該參數設置Master節點上為每個客戶端連接會話(session)所使用的,在事務過程中臨時存儲日志數據的緩存大小。如果沒有使用支持事務的引擎,可以忽略這個值的設置。但是一般來說我們都會使用InnoDB引擎,所以該值最好設置成1M——2M,如果經常會執行較復雜的事務,則可以適當加大為3M——4M。
max_binlog_cache_size:該值表示整個MySQL服務中,能夠使用的binlog_cache區域的最大值。該值不以session為單位,而是對全局進行設置。
max_binlog_size : 該參數設置單個binlog文件的最大大小。MySQL服務為了避免binlog日志出錯或者Salve同步失敗,會在兩種情況下創建新的binlog文件:一種情況是MySQL服務重啟后,另一種情況是binlog文件的大小達到一個設定的閥值(默認為1GB)。max_binlog_size參數就是設置這個閥值的。
完成my.cnf文件的更改后,重啟Linux MySql服務新的配置就生效了。接下來需要在Master節點中設置可供連接的Salve節點信息,包括進行Replicaion同步的用戶和密碼信息:
# 只用MySQL客戶端,都可以進行設置:# 這里我們直接使用root賬號進行同步,但是生產環境下不建議這樣使用> grant replication slave on *.* to root@192.168.61.141 identified by ’123456’
# 通過以下命令,可以查看設置完成后的Master節點工作狀態
> show master status;
+----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------+----------+--------------+------------------+-------------------+
| kp2-bin.000002 | 404 | qiang | | |
+----------------+----------+--------------+------------------+-------------------+
以上master節點狀態的描述中,File屬性說明了當前二進制日志文件的名稱,它的默認位置在Linux操作系統下的var/lib/mysql目錄下。Position屬性說明了當前已完成日志同步的數據點在日志文件中的位置。Binlog_Do_DB屬性是我們之前設置的,需要進行Replicaion操作的數據庫名稱,Binlog_Ignore_DB屬性就是明確忽略的,不需要進行Replicaion操作的數據庫名稱。
2-2-2、設置Salve服務器
完成MySQL Master服務的配置后,我們來看看Salve節點該如何進行設置。這里我們只演示一個Salve節點的設置,如果您還要在集群中增加新的Salve節點,那么配置過程都是類似的。無非是要注意在Master節點上增加新的Salve節點描述信息。
首先我們還是需要設置Salve節點的my.cnf文件:
# my.cnf文件中沒有涉及Replicaion機制的配置信息,就不在這里列出了......# 開啟日志log-bin
sync_relay_log=1
# 必須為這個MySQL服務節點設置一個集群中唯一的server id信息
server_id=140
......
在MySQL官方文檔中也詳細描述了中繼日志的各種控制參數,這里我們只使用了sync_relay_log參數。這個參數說明了Salve節點在成功接受到多少次Master同步日志信息后,才刷入中繼日志文件。這個參數可以設置為1到N的任意一個值,當然設置為1的情況下雖然會消耗一些性能,但對于日志數據來說卻是最安全的。
Salve的設置相對簡單,接下來我們需要在Salve端開啟相應的同步功能。主要是指定用于同步的Master服務地址、用戶和密碼信息:
# 請注意這里設置的用戶名和密碼信息要和Master上的設置一致# 另外master log file所指定的文件名也必須和Master上使用的日志文件名一致> change master to master_host=’192.168.61.140’,master_user=’root’,master_password=’123456’, master_log_file=’kp2-bin.000002’,master_log_pos=120;
# 啟動Savle同步
> start slave;
# 然后我們就可以使用以下命令查看salve節點的同步狀態
> show slave status;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.61.140
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: kp2-bin.000002
Read_Master_Log_Pos: 404
Relay_Log_File: vm2-relay-bin.000002
Relay_Log_Pos: 565
Relay_Master_Log_File: kp2-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Master_Server_Id: 140
Master_UUID: 19632f72-9a90-11e6-82bd-000c290973df
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log;
waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
......
Auto_Position: 0
完成以上過程,一主一從的MySQL集群就配置完成了。
2-3、一主多從方案的使用建議
一主多從的MySQL集群方案,已經可以解決大部分系統結構化數據存儲的性能要求。特別是那種數據查詢頻率/次數遠遠大于數據寫入頻率/次數的業務場景,例如電商系統的商品模塊、物流系統的車輛/司機信息模塊、電信CRM系統的客戶信息模塊、監控系統中保存的基本日志數據。但是這種架構方案并不能解決所有的問題,而且方案本身有一些明顯的問題(后文詳細討論),所以在這里本文需要為各位將要使用類似MySQL集群方案的讀者提供一些使用建議。
Master單節點性能應該足夠強大,且只負責數據寫入操作:一主多從的MySQL集群方式主要針對讀密集型業務系統,其主要目標是將MySQL服務的讀寫壓力進行分離。所以Master節點需要集中精力處理業務的寫操作請求,這也就意味著業務系統所有的寫操作壓力都集中到了這一個節點上(write業務操作)。我們暫且不去分析這個現象可能導致的問題(后續內容會提到這種做法的問題),但這至少要求Master節點的性能足夠強大。這里的性能不單單指通過MySQL InnoDB引擎提供的各種配置(一般我們使用InnoDB引擎),并結合業務特點所盡可能榨取的性能,最根本的還需要提升Master節點的硬件性能。
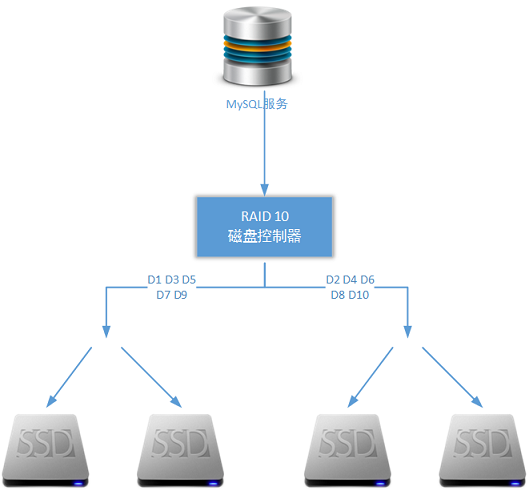
使用固態硬盤作為MySQL服務的塊存儲基礎,并使用RAID 10磁盤陣列作為硬件層構建方案——這是生產環境下單個MySQL服務節點的基本組成邏輯,當然讀者可以視自己生產環境下的的實際容量和性能要求進行必要的調整:
應使用一個獨立的Salve節點作為備用的Master節點,雖然這種方式不可作為異地多活方案的基礎但可作為本地高可用方案的實現基礎。當然,為了防止由于日志錯誤導致的備份失敗,這個備份的Salve節點也可以采用MySQL Replicaion機制以外的第三方同步機制,例如:Rsync、DRBD。Rsync是筆者在工作實踐中經常使用的,進行MySQL數據增量同步的方式,而DRBD的差異塊同步方式是互聯網上能夠找到最多資料的方式:
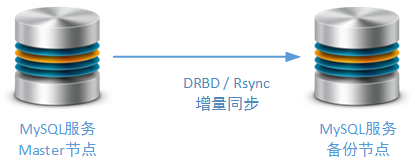
在后續的文章中,我們還會專門討論針對Master節點的集群調整方案,并且建議讀者如何使用適合系統自身業務的高可用方案。例如使用Keepalived / Heartbeat進行主備Master節點的切換:
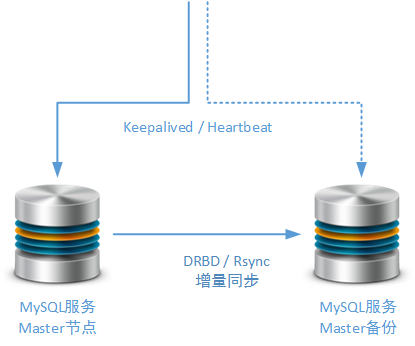
復雜的統計查詢需要專門的Salve節點進行支持。參與生產環境實時業務處理的任何MySQL服務節點,在這些服務節點上所運行的SQL查詢應該盡可能簡單,并且需要使用索引對檢索進行支持。特別是數據量非常大的數據表,必須保證所有的檢索操作都有索引提供支持,否則Table Full Scan的檢索過濾方式不但會拖慢檢索操作本身,還可能會明顯拖慢其它的事務操作。通過MySQL提供的執行計劃功能,技術人員能夠很方便實現以上的要求。如果您的業務系統存在復雜的業務查詢要求,例如周期性的財務流水報表,周期性的業務分組統計報表等,那么您最好專門準備一個(或多個)脫離實時業務的Salve節點,完成這個工作。
3、方案暴露的問題但是這種MySQL集群方案也存在很多問題需要進一步改進。在后續的文章中,我們會依次討論MySQL集群中還存在的以下問題:
面向上層系統的問題:在MySQL一主多從集群中,存在過個服務節點。那么當上層業務系統進行數據庫操作時(無論是寫操作還是讀操作),是否需要明確知道這些具體的服務節點,并進行連接呢?要知道,當上層業務系統需要控制的要素變得原來越多時,需要業務系統開發人員投入的維護精力就會呈幾何級增長。
高可用層面的問題:在MySQL一主多從集群中,雖然存在多個Salve節點(read業務性質節點),但是一般只存在一個Master節點(write業務性質節點)。某一個(或多個)Salve節點崩潰了,不會對整個集群造成太大影響(但可能影響上層業務系統的某一個子系統)。那么MySQL集群的短板在于只有一個Master節點——一旦它崩潰了,整個集群就基本上無法正常工作。所以我們必須想一些辦法改變這個潛在風險。
來自:http://www.uml.org.cn/sjjm/201611072.asp
相關文章:
 網公網安備
網公網安備