JavaScript正則表達式這幾個細節你真的知道?
粗淺的編寫正則表達式,是造成性能瓶頸的主要原因。如下:
var reg1 = /(A+A+)+B/; var reg2 = /AA+B/;
上述兩個正則表達式,匹配效果是一樣的,但是,效率就相差太遠了,甚至在與少量字符串匹配時,reg1就會造成你瀏覽器卡死。
不信?我們可以測試下。
首先,我們聲明一個字符串變量str,同時賦予一個包含20個A的字符串給str,采用match方法與上述reg1、reg2進行匹配測試,如下:
var str = ’AAAAAAAAAAAAAAAAAAAA’;str.match(reg1);str.match(reg2);
在瀏覽器中運行該段代碼,發現一切正常嘛。
然而,隨著,我們不斷向變量str中添加A后,重復測試,在某一刻(取決于你的瀏覽器),reg1就會讓我們的瀏覽器掛起,但,回頭看看最終的str字符串長度,卻還不到50。而,reg2卻安然無恙。
心里有一絲疑問,是什么造成了它們如此巨大的差別?以后我們在寫正則表達式時,又該如何避免防范這類問題呢?
那么,接下來,我們就有必要深入理解JavaScript正則表達式的內部執行原理了。
如果,在此你還不是很了解正則表達式,那么可以參考如下兩篇博客后,再前來,小生在此等候。
正則表達式工作原理為了高效的使用正則表達式,理解它們的工作原理是很重要的。
具體如下:
Step1.編譯
當我們創建一個正則表達式(字面量或者RegExp對象)后,瀏覽器會檢查該正則的模板是否符合標準,然后將其轉化成內部代碼,用于執行匹配工作。
所以,如果我們將正則表達式賦予一個變量,可以避免重復執行該 ‘編譯’ 步驟。
Step2.設置開始位置
當我們使用Step1中編譯后的正則表達式時,首先它將確定從目標字符串中什么位置進行匹配。通常,是目標字符串的起始位置,或者由正則表達式的lastIndex屬性指定。
但是,當它從Step4(匹配失敗)中返回時,該位置則為匹配失敗的位置的下一個位置。
Step3.正則匹配
當經歷Step2后,正則表達式將從指定位置,從左到右,與目標字符串,逐個匹配。若,正則表達式在匹配過程中,遇到某個字元匹配不了時,它不會立即失敗,而是嘗試回溯到最近一個決策點,然后在剩余選項中選擇一個,以求繼續能匹配。
Step4.匹配結果
當經歷Step3后,發現能與正則匹配成功的子字符串,那么就匹配成功。如果,經歷了Step3后,發現沒有能與正則匹配的子字符串,那么,它將回到Step2,繼續。只有當目標字符串中的每個字符(以及最后一個字符后面的位置)都經歷了Step3后,仍沒有找到匹配項,才宣布失敗。
下面就舉個例子,使我們更透徹地明白以上4步。
如下:
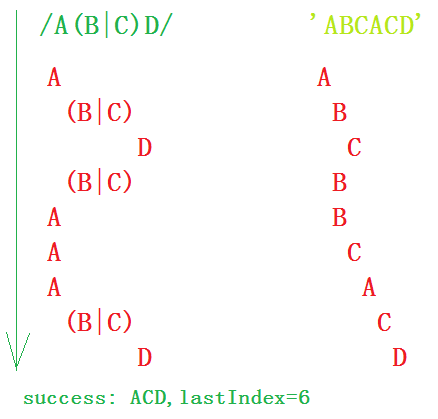
var reg = /A(B|C)D/g; var str = ’ABCACD’;reg.exec(str);
① 首先,瀏覽器將解析reg正則表達式(Step1)。
② 然后,由于是首次匹配,所以確認開始位置即為字符串起始位置(Step2)。
③ 首先由正則的第一個字元A與字符串起始位置字符A匹配,成功,并在之后的位置記錄一個決策點,因為后面有分支嘛;然后由 (B|C)分支中的B選項去匹配字符串的B,發現匹配;然后再由正則下一個字元D去匹配目標字符串第三個字符C,發現不匹配,但是并沒有放棄,而是回溯,查看是否有決策點,發現有,回溯到就近一個決策點(字符串首字母A之后的那個位置上),嘗試利用第二個分支選項C去匹配字符串第二個字符B,發現不匹配,回溯,查詢是否還有其他分支選項,發現沒有,然后宣布該次失敗(Step3)。
④ 經歷Step3后,發現沒有與正則匹配的子字符串,但是,與之匹配的目標字符串的匹配位置并不是最后一個位置,所以,回到Step2,從目標字符串的下一個位置(即,字符串首字母A之后的那個位置上)開始匹配。首先由正則表達式的第一個字元A與目標字符串B匹配,不成功,又無回溯點,故而,進入Step4,判斷是否是最后一個位置,發現不是,又跳到Step2中繼續。
⑤ 就這樣一步一步,來到了目標字符串的第四個位置,首先A去與目標字符串的第三個字符A匹配,成功;接下來就是由分支(B|C),去匹配C,首先由分支中的第一個選項B去與C匹配,發現沒有成功,回溯到就近一個決策點,嘗試利用第二個分支選項C匹配,成功,緊接著D也成功了。
⑥ 匹配成功,并將lastIndex置為6。
上述 “正則表達式工作原理” 一小節,Step3中的回溯我們是一筆帶過的。但是,可不要忽略了,回溯在正則中是非常重要的,如果理解得不明白,我們在編寫正則時,很容易造成回溯失控。
下面我們就來一起看看回溯在正則表達式中的運用。
正則表達式中有兩種情況,會制造回溯點:
-分支(通過|操作符)
-量詞(諸如*,+?,或者{…})
下面我們就分別舉例來看看。
分支和回溯
對于分支,詳見 ‘正則表達式工作原理’ 小節中Demo。
量詞和回溯
在量詞中,有貪婪量詞(諸如*,+)和非貪婪量詞(諸如*?,+?)之分。所以回溯形式對于它們而言也就有差別咯。我們首先寫個demo看看貪婪量詞是怎么回溯的。
Demo如下:
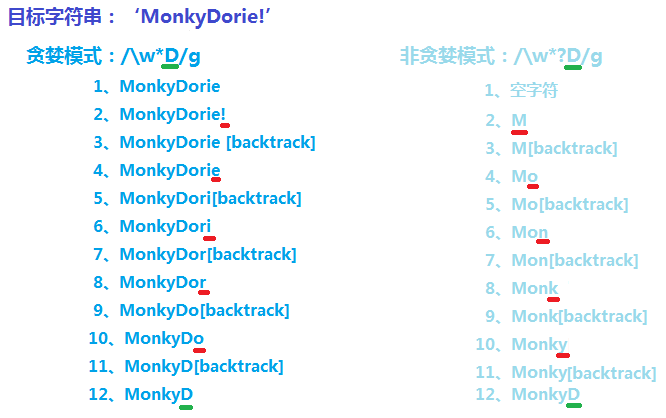
var reg = /w*D/g; var str = ’MonkyDorie!’;reg.exec(str);
就上述貪婪模式匹配流程如下:
提醒:正則表達式reg中w表示匹配“字母、數字或下劃線”,*這個貪婪量詞表示重復匹配零次或者多次,由于是貪婪量詞,故而它會盡可能多的匹配。
① 首先,正則中的w*與目標字符串匹配,會一直匹配到‘!’之前,即’MonkyDorie’,并且,每個匹配位置都會記錄一個決策點,便于回溯。
② 然后,由正則中的剩余字元D與字符串中!匹配,匹配失敗;但是,它并沒有放棄(因為在此之前,記錄了決策點),而是回溯到就近一個決策點(字符e的前一個位置),然后正則D與字符e匹配,匹配失敗;再回溯到就近一個決策點(字符i的前一個位置),然后正則D與字符i匹配,匹配失敗;就這樣一直回溯到字符D的前一個位置時,正則D與字符D匹配,匹配成功,并置lastIndex為6。
好了,這就是上述貪婪匹配流程。
隨后,我們將上述Demo中的正則表達式,稍微調整下,在*后面加上?,變成非貪婪模式,看看非貪婪量詞是怎么回溯的。
Demo如下:
var reg = /w*?D/g; var str = ’MonkyDorie!’;reg.exec(str);
就上述非貪婪模式匹配流程如下:
提醒:正則表達式reg中w表示匹配“字母、數字或下劃線”,*?是個非貪婪量詞,也表示重復匹配零次或者多次,但是由于是非貪婪量詞,故而它會盡可能少的匹配。
首先,正則中的w*?會選擇匹配零個字符(盡可能少的匹配),并將第一個位置(字符M的前一個位置)記錄一個決策點,繼而輪到字元D與字符串字符M匹配,匹配失敗;回溯到就近一個決策點(字符M的前一個位置),然后w*?選擇匹配一個字符M,并記錄一個回溯點(第二個字符o的前一個位置),繼而輪到字元D與字符串字符o匹配,匹配失敗;回溯到就近一個決策點(字符o的前一個位置),就這樣一步一步,當w*?選擇匹配五個字符Monky時,繼而輪到字元D與字符串字符D匹配,匹配成功,并置lastIndex為6.
上述兩Demo,對比圖如下:
正如上述 ‘回溯’ 小節中談到,重復量詞和分支會記錄決策點,引起回溯。但是,如果在實際需求中,我們不想讓它們記錄決策點呢—因為回溯太多就會導致回溯失控,影響性能,正如我們在 ‘前言’ 中看到的那樣。
一些正則表達式引擎,支持一種叫做原子組的屬性。原子組,寫作(?>…),省略號表示任意正則表達式模板。存在原子組中的正則表達式組中的任何決策點都將被丟棄。利用原子組,我們就可以在必要時,消除由重復量詞和分支記錄的決策點了。
但,在JavaScript中不支持原子組,怎么辦呢?
我們可以利用前瞻來模擬原子組,但是,前瞻在整個匹配過程中,是不消耗字符的,它只是檢查自己包含的模板是否能在當前位置匹配。然而,我們又可以利用后向引用解決此問題,如下:
(?=(pattern to make atomic))1
好了,針對 ‘利用前瞻和后向引用避免回溯’ 一節,我們寫個Demo,自我測試下:
var str = ’ABCDM’; //目標字符串 var reg1 = /w*M/; //貪婪模式 var reg2 = /(?=(w*))1M/; //貪婪模式,使用前瞻和后向引用 var reg3 = /w*?M/; //非貪婪模式 var reg4 = /(?=(w*?))M/; //非貪婪模式,使用前瞻和后向引用
對于以下匹配結果,各位看官答對否:
str.match(reg1);str.match(reg2);str.match(reg3);str.match(reg4);
來自:http://www.cnblogs.com/giggle/p/5990486.html
相關文章:

 網公網安備
網公網安備