Java 中的語法糖,真甜
我把自己以往的文章匯總成為了 Github ,歡迎各位大佬 starhttps://github.com/crisxuan/bestJavaer
我們在日常開發(fā)中經(jīng)常會使用到諸如泛型、自動拆箱和裝箱、內(nèi)部類、增強(qiáng) for 循環(huán)、try-with-resources 語法、lambda 表達(dá)式等,我們只覺得用的很爽,因?yàn)檫@些特性能夠幫助我們減輕開發(fā)工作量;但我們未曾認(rèn)真研究過這些特性的本質(zhì)是什么,那么這篇文章,cxuan 就來為你揭開這些特性背后的真相。
語法糖
在聊之前我們需要先了解一下 語法糖 的概念:語法糖(Syntactic sugar),也叫做糖衣語法,是英國科學(xué)家發(fā)明的一個(gè)術(shù)語,通常來說使用語法糖能夠增加程序的可讀性,從而減少程序代碼出錯(cuò)的機(jī)會,真是又香又甜。
語法糖指的是計(jì)算機(jī)語言中添加的某種語法,這種語法對語言的功能并沒有影響,但是更方便程序員使用。因?yàn)?Java 代碼需要運(yùn)行在 JVM 中,JVM 是并不支持語法糖的,語法糖在程序編譯階段就會被還原成簡單的基礎(chǔ)語法結(jié)構(gòu),這個(gè)過程就是解語法糖。所以在 Java 中,真正支持語法糖的是 Java 編譯器,真是換湯不換藥,萬變不離其宗,關(guān)了燈都一樣。。。。。。
下面我們就來認(rèn)識一下 Java 中的這些語法糖
泛型
泛型是一種語法糖。在 JDK1.5 中,引入了泛型機(jī)制,但是泛型機(jī)制的本身是通過類型擦除 來實(shí)現(xiàn)的,在 JVM 中沒有泛型,只有普通類型和普通方法,泛型類的類型參數(shù),在編譯時(shí)都會被擦除。泛型并沒有自己獨(dú)特的 Class類型。如下代碼所示
List<Integer> aList = new ArrayList();List<String> bList = new ArrayList();System.out.println(aList.getClass() == bList.getClass());
List<Ineger> 和 List<String> 被認(rèn)為是不同的類型,但是輸出卻得到了相同的結(jié)果,這是因?yàn)椋盒托畔⒅淮嬖谟诖a編譯階段,在進(jìn)入 JVM 之前,與泛型相關(guān)的信息會被擦除掉,專業(yè)術(shù)語叫做類型擦除。但是,如果將一個(gè) Integer 類型的數(shù)據(jù)放入到 List<String> 中或者將一個(gè) String 類型的數(shù)據(jù)放在 List<Ineger> 中是不允許的。
如下圖所示

無法將一個(gè) Integer 類型的數(shù)據(jù)放在 List<String> 和無法將一個(gè) String 類型的數(shù)據(jù)放在 List<Integer> 中是一樣會編譯失敗。
自動拆箱和自動裝箱
自動拆箱和自動裝箱是一種語法糖,它說的是八種基本數(shù)據(jù)類型的包裝類和其基本數(shù)據(jù)類型之間的自動轉(zhuǎn)換。簡單的說,裝箱就是自動將基本數(shù)據(jù)類型轉(zhuǎn)換為包裝器類型;拆箱就是自動將包裝器類型轉(zhuǎn)換為基本數(shù)據(jù)類型。
我們先來了解一下基本數(shù)據(jù)類型的包裝類都有哪些

也就是說,上面這些基本數(shù)據(jù)類型和包裝類在進(jìn)行轉(zhuǎn)換的過程中會發(fā)生自動裝箱/拆箱,例如下面代碼
Integer integer = 66; // 自動拆箱int i1 = integer; // 自動裝箱
上面代碼中的 integer 對象會使用基本數(shù)據(jù)類型來進(jìn)行賦值,而基本數(shù)據(jù)類型 i1 卻把它賦值給了一個(gè)對象類型,一般情況下是不能這樣操作的,但是編譯器卻允許我們這么做,這其實(shí)就是一種語法糖。這種語法糖使我們方便我們進(jìn)行數(shù)值運(yùn)算,如果沒有語法糖,在進(jìn)行數(shù)值運(yùn)算時(shí),你需要先將對象轉(zhuǎn)換成基本數(shù)據(jù)類型,基本數(shù)據(jù)類型同時(shí)也需要轉(zhuǎn)換成包裝類型才能使用其內(nèi)置的方法,無疑增加了代碼冗余。
那么自動拆箱和自動裝箱是如何實(shí)現(xiàn)的呢?
其實(shí)這背后的原理是編譯器做了優(yōu)化。將基本類型賦值給包裝類其實(shí)是調(diào)用了包裝類的 valueOf() 方法創(chuàng)建了一個(gè)包裝類再賦值給了基本類型。
int i1 = Integer.valueOf(1);
而包裝類賦值給基本類型就是調(diào)用了包裝類的 xxxValue() 方法拿到基本數(shù)據(jù)類型后再進(jìn)行賦值。
Integer i1 = new Integer(1).intValue();
我們使用 javap -c 反編譯一下上面的自動裝箱和自動拆箱來驗(yàn)證一下

可以看到,在 Code 2 處調(diào)用 invokestatic 的時(shí)候,相當(dāng)于是編譯器自動為我們添加了一下 Integer.valueOf 方法從而把基本數(shù)據(jù)類型轉(zhuǎn)換為了包裝類型。
在 Code 7 處調(diào)用了 invokevirtual 的時(shí)候,相當(dāng)于是編譯器為我們添加了 Integer.intValue() 方法把 Integer 的值轉(zhuǎn)換為了基本數(shù)據(jù)類型。
枚舉
我們在日常開發(fā)中經(jīng)常會使用到 enum 和 public static final ... 這類語法。那么什么時(shí)候用 enum 或者是 public static final 這類常量呢?好像都可以。
但是在 Java 字節(jié)碼結(jié)構(gòu)中,并沒有枚舉類型。枚舉只是一個(gè)語法糖,在編譯完成后就會被編譯成一個(gè)普通的類,也是用 Class 修飾。這個(gè)類繼承于 java.lang.Enum,并被 final 關(guān)鍵字修飾。
我們舉個(gè)例子來看一下
public enum School { STUDENT, TEACHER;}
這是一個(gè) School 的枚舉,里面包括兩個(gè)字段,一個(gè)是 STUDENT ,一個(gè)是 TEACHER,除此之外并無其他。
下面我們使用 javap 反編譯一下這個(gè) School.class 。反編譯完成之后的結(jié)果如下

從圖中我們可以看到,枚舉其實(shí)就是一個(gè)繼承于 java.lang.Enum 類的 class 。而里面的屬性 STUDENT 和 TEACHER 本質(zhì)也就是 public static final 修飾的字段。這其實(shí)也是一種編譯器的優(yōu)化,畢竟 STUDENT 要比 public static final School STUDENT 的美觀性、簡潔性都要好很多。
除此之外,編譯器還會為我們生成兩個(gè)方法,values() 方法和 valueOf 方法,這兩個(gè)方法都是編譯器為我們添加的方法,通過使用 values() 方法可以獲取所有的 Enum 屬性值,而通過 valueOf 方法用于獲取單個(gè)的屬性值。
注意,Enum 的 values() 方法不屬于 JDK API 的一部分,在 Java 源碼中,沒有 values() 方法的相關(guān)注釋。
用法如下
public enum School { STUDENT('Student'), TEACHER('Teacher'); private String name; School(String name){ this.name = name; } public String getName() { return name; } public static void main(String[] args) { System.out.println(School.STUDENT.getName()); School[] values = School.values(); for(School school : values){ System.out.println('name = '+ school.getName()); } }}
內(nèi)部類
內(nèi)部類是 Java 一個(gè)小眾 的特性,我之所以說小眾,并不是說內(nèi)部類沒有用,而是我們?nèi)粘i_發(fā)中其實(shí)很少用到,但是翻看 JDK 源碼,發(fā)現(xiàn)很多源碼中都有內(nèi)部類的構(gòu)造。比如常見的 ArrayList 源碼中就有一個(gè) Itr 內(nèi)部類繼承于 Iterator 類;再比如 HashMap 中就構(gòu)造了一個(gè) Node 繼承于 Map.Entry<K,V> 來表示 HashMap 的每一個(gè)節(jié)點(diǎn)。
Java 語言中之所以引入內(nèi)部類,是因?yàn)橛行r(shí)候一個(gè)類只想在一個(gè)類中有用,不想讓其在其他地方被使用,也就是對外隱藏內(nèi)部細(xì)節(jié)。
內(nèi)部類其實(shí)也是一個(gè)語法糖,因?yàn)槠渲皇且粋€(gè)編譯時(shí)的概念,一旦編譯完成,編譯器就會為內(nèi)部類生成一個(gè)單獨(dú)的class 文件,名為 outer$innter.class。
下面我們就根據(jù)一個(gè)示例來驗(yàn)證一下。
public class OuterClass { private String label; class InnerClass { public String linkOuter(){ return label = 'inner'; } } public static void main(String[] args) { OuterClass outerClass = new OuterClass(); InnerClass innerClass = outerClass.new InnerClass(); System.out.println(innerClass.linkOuter()); }}
上面這段編譯后就會生成兩個(gè) class 文件,一個(gè)是 OuterClass.class ,一個(gè)是 OuterClass$InnerClass.class ,這就表明,外部類可以鏈接到內(nèi)部類,內(nèi)部類可以修改外部類的屬性等。
我們來看一下內(nèi)部類編譯后的結(jié)果
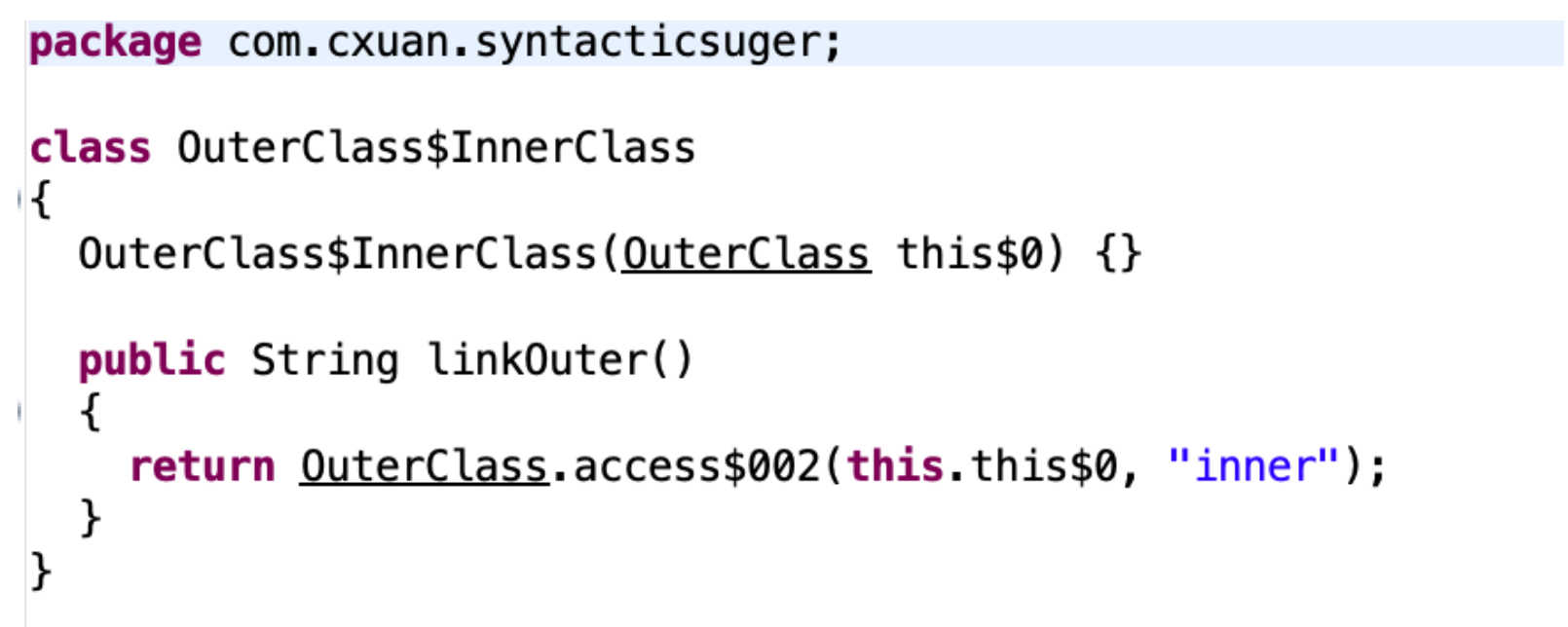
如上圖所示,內(nèi)部類經(jīng)過編譯后的 linkOuter() 方法會生成一個(gè)指向外部類的 this 引用,這個(gè)引用就是連接外部類和內(nèi)部類的引用。
變長參數(shù)
變長參數(shù)也是一個(gè)比較小眾的用法,所謂變長參數(shù),就是方法可以接受長度不定確定的參數(shù)。一般我們開發(fā)不會使用到變長參數(shù),而且變長參數(shù)也不推薦使用,它會使我們的程序變的難以處理。但是我們有必要了解一下變長參數(shù)的特性。
其基本用法如下
public class VariableArgs { public static void printMessage(String... args){ for(String str : args){ System.out.println('str = ' + str); } } public static void main(String[] args) { VariableArgs.printMessage('l','am','cxuan'); }}
變長參數(shù)也是一種語法糖,那么它是如何實(shí)現(xiàn)的呢?我們可以猜測一下其內(nèi)部應(yīng)該是由數(shù)組構(gòu)成,否則無法接受多個(gè)值,那么我們反編譯看一下是不是由數(shù)組實(shí)現(xiàn)的。

可以看到,printMessage() 的參數(shù)就是使用了一個(gè)數(shù)組來接收,所以千萬別被變長參數(shù)忽悠了!
變長參數(shù)特性是在 JDK 1.5 中引入的,使用變長參數(shù)有兩個(gè)條件,一是變長的那一部分參數(shù)具有相同的類型,二是變長參數(shù)必須位于方法參數(shù)列表的最后面。
增強(qiáng) for 循環(huán)
為什么有了普通的 for 循環(huán)后,還要有增強(qiáng) for 循環(huán)呢?想一下,普通 for 循環(huán)你不是需要知道遍歷次數(shù)?每次還需要知道數(shù)組的索引是多少,這種寫法明顯有些繁瑣。增強(qiáng) for 循環(huán)與普通 for 循環(huán)相比,功能更強(qiáng)并且代碼更加簡潔,你無需知道遍歷的次數(shù)和數(shù)組的索引即可進(jìn)行遍歷。
增強(qiáng) for 循環(huán)的對象要么是一個(gè)數(shù)組,要么實(shí)現(xiàn)了 Iterable 接口。這個(gè)語法糖主要用來對數(shù)組或者集合進(jìn)行遍歷,其在循環(huán)過程中不能改變集合的大小。
public static void main(String[] args) { String[] params = new String[]{'hello','world'}; //增強(qiáng)for循環(huán)對象為數(shù)組 for(String str : params){ System.out.println(str); } List<String> lists = Arrays.asList('hello','world'); //增強(qiáng)for循環(huán)對象實(shí)現(xiàn)Iterable接口 for(String str : lists){ System.out.println(str); }}
經(jīng)過編譯后的 class 文件如下
public static void main(String[] args) { String[] params = new String[]{'hello', 'world'}; String[] lists = params; int var3 = params.length; //數(shù)組形式的增強(qiáng)for退化為普通for for(int str = 0; str < var3; ++str) { String str1 = lists[str]; System.out.println(str1); } List var6 = Arrays.asList(new String[]{'hello', 'world'}); Iterator var7 = var6.iterator(); //實(shí)現(xiàn)Iterable接口的增強(qiáng)for使用iterator接口進(jìn)行遍歷 while(var7.hasNext()) { String var8 = (String)var7.next(); System.out.println(var8); }}
如上代碼所示,如果對數(shù)組進(jìn)行增強(qiáng) for 循環(huán)的話,其內(nèi)部還是對數(shù)組進(jìn)行遍歷,只不過語法糖把你忽悠了,讓你以一種更簡潔的方式編寫代碼。
而對繼承于 Iterator 迭代器進(jìn)行增強(qiáng) for 循環(huán)遍歷的話,相當(dāng)于是調(diào)用了 Iterator 的 hasNext() 和 next() 方法。
Switch 支持字符串和枚舉
switch 關(guān)鍵字原生只能支持整數(shù)類型。如果 switch 后面是 String 類型的話,編譯器會將其轉(zhuǎn)換成 String 的hashCode 的值,所以其實(shí) switch 語法比較的是 String 的 hashCode 。
如下代碼所示
public class SwitchCaseTest { public static void main(String[] args) { String str = 'cxuan'; switch (str){ case 'cuan': System.out.println('cuan'); break; case 'xuan': System.out.println('xuan'); break; case 'cxuan': System.out.println('cxuan'); break; default: break; } }}
我們反編譯一下,看看我們的猜想是否正確
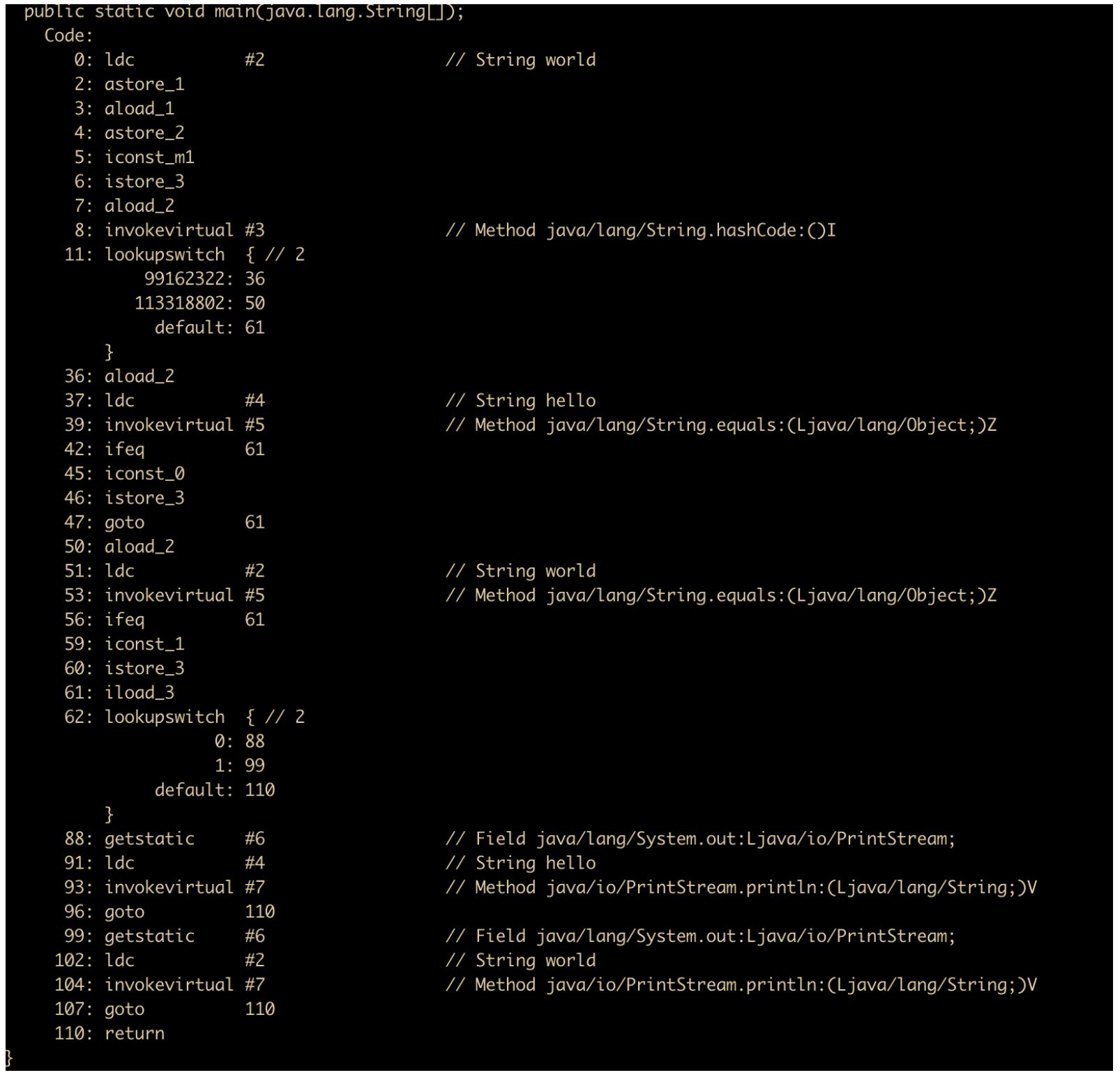
根據(jù)字節(jié)碼可以看到,進(jìn)行 switch 的實(shí)際是 hashcode 進(jìn)行判斷,然后通過使用 equals 方法進(jìn)行比較,因?yàn)樽址锌赡軙a(chǎn)生哈希沖突的現(xiàn)象。
條件編譯
這個(gè)又是讓小伙伴們摸不著頭腦了,什么是條件編譯呢?其實(shí),如果你用過 C 或者 C++ 你就知道可以通過預(yù)處理語句來實(shí)現(xiàn)條件編譯。
那么什么是條件編譯呢?
一般情況下,源程序中所有的行都參加編譯。但有時(shí)希望對其中一部分內(nèi)容只在滿足一定條件下才進(jìn)行編譯,即對一部分內(nèi)容指定編譯條件,這就是 條件編譯(conditional compile)。
#define DEBUG #IFDEF DEBUUG /* code block 1 */ #ELSE /* code block 2 */ #ENDIF
但是在 Java 中沒有預(yù)處理和宏定義這些內(nèi)容,那么我們想實(shí)現(xiàn)條件編譯,應(yīng)該怎樣做呢?
使用 final + if 的組合就可以實(shí)現(xiàn)條件編譯了。如下代碼所示
public static void main(String[] args) { final boolean DEBUG = true; if (DEBUG) { System.out.println('Hello, world!'); } else { System.out.println('nothing'); }}
這段代碼會發(fā)生什么?我們反編譯看一下

我們可以看到,我們明明是使用了 if ...else 語句,但是編譯器卻只為我們編譯了 DEBUG = true 的條件,
所以,Java 語法的條件編譯,是通過判斷條件為常量的 if 語句實(shí)現(xiàn)的,編譯器不會為我們編譯分支為 false 的代碼。
斷言
你在 Java 中使用過斷言作為日常的判斷條件嗎?
斷言:也就是所謂的 assert 關(guān)鍵字,是 jdk 1.4 后加入的新功能。它主要使用在代碼開發(fā)和測試時(shí)期,用于對某些關(guān)鍵數(shù)據(jù)的判斷,如果這個(gè)關(guān)鍵數(shù)據(jù)不是你程序所預(yù)期的數(shù)據(jù),程序就提出警告或退出。當(dāng)軟件正式發(fā)布后,可以取消斷言部分的代碼。它也是一個(gè)語法糖嗎?現(xiàn)在我不告訴你,我們先來看一下 assert 如何使用。
//這個(gè)成員變量的值可以變,但最終必須還是回到原值5 static int i = 5; public static void main(String[] args) { assert i == 5; System.out.println('如果斷言正常,我就被打印'); }
如果要開啟斷言檢查,則需要用開關(guān) -enableassertions 或 -ea 來開啟。其實(shí)斷言的底層實(shí)現(xiàn)就是 if 判斷,如果斷言結(jié)果為 true,則什么都不做,程序繼續(xù)執(zhí)行,如果斷言結(jié)果為 false,則程序拋出 AssertError 來打斷程序的執(zhí)行。
assert 斷言就是通過對布爾標(biāo)志位進(jìn)行了一個(gè) if 判斷。
try-with-resources
JDK 1.7 開始,java引入了 try-with-resources 聲明,將 try-catch-finally 簡化為 try-catch,這其實(shí)是一種語法糖,在編譯時(shí)會進(jìn)行轉(zhuǎn)化為 try-catch-finally 語句。新的聲明包含三部分:try-with-resources 聲明、try 塊、catch 塊。它要求在 try-with-resources 聲明中定義的變量實(shí)現(xiàn)了 AutoCloseable 接口,這樣在系統(tǒng)可以自動調(diào)用它們的 close 方法,從而替代了 finally 中關(guān)閉資源的功能。
如下代碼所示
public class TryWithResourcesTest { public static void main(String[] args) { try(InputStream inputStream = new FileInputStream(new File('xxx'))) { inputStream.read(); }catch (Exception e){ e.printStackTrace(); } }}
我們可以看一下 try-with-resources 反編譯之后的代碼

可以看到,生成的 try-with-resources 經(jīng)過編譯后還是使用的 try...catch...finally 語句,只不過這部分工作由編譯器替我們做了,這樣能讓我們的代碼更加簡潔,從而消除樣板代碼。
字符串相加
這個(gè)想必大家應(yīng)該都知道,字符串的拼接有兩種,如果能夠在編譯時(shí)期確定拼接的結(jié)果,那么使用 + 號連接的字符串會被編譯器直接優(yōu)化為相加的結(jié)果,如果編譯期不能確定拼接的結(jié)果,底層會直接使用 StringBuilder 的 append 進(jìn)行拼接,如下圖所示。
public class StringAppendTest { public static void main(String[] args) { String s1 = 'I am ' + 'cxuan'; String s2 = 'I am ' + new String('cxuan'); String s3 = 'I am '; String s4 = 'cxuan'; String s5 = s3 + s4; }}
上面這段代碼就包含了兩種字符串拼接的結(jié)果,我們反編譯看一下

首先來看一下 s1 ,s1 因?yàn)?= 號右邊是兩個(gè)常量,所以兩個(gè)字符串拼接會被直接優(yōu)化成為 I am cxuan。而 s2 由于在堆空間中分配了一個(gè) cxuan 對象,所以 + 號兩邊進(jìn)行字符串拼接會直接轉(zhuǎn)換為 StringBuilder ,調(diào)用其 append 方法進(jìn)行拼接,最后再調(diào)用 toString() 方法轉(zhuǎn)換成字符串。
而由于 s5 進(jìn)行拼接的兩個(gè)對象在編譯期不能判定其拼接結(jié)果,所以會直接使用 StringBuilder 進(jìn)行拼接。
學(xué)習(xí)語法糖的意義
互聯(lián)網(wǎng)時(shí)代,有很多標(biāo)新立異的想法和框架層出不窮,但是,我們對于學(xué)習(xí)來說應(yīng)該抓住技術(shù)的核心。然而,軟件工程是一門協(xié)作的藝術(shù),對于工程來說如何提高工程質(zhì)量,如何提高工程效率也是我們要關(guān)注的,既然這些語法糖能輔助我們以更好的方式編寫備受歡迎的代碼,我們程序員為什么要 抵制 呢?
語法糖也是一種進(jìn)步,這就和你寫作文似的,大白話能把故事講明白的它就沒有語言優(yōu)美、酣暢淋漓的把故事講生動的更令人喜歡。
我們要在敞開懷抱擁抱變化的同時(shí)也要掌握其 屠龍之技。
到此這篇關(guān)于Java 中的語法糖,真甜的文章就介紹到這了,更多相關(guān)Java 語法糖內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備