如何理解Java線程池及其使用方法
多線程的異步執(zhí)行方式,雖然能夠最大限度發(fā)揮多核計(jì)算機(jī)的計(jì)算能力,但是如果不加控制,反而會(huì)對(duì)系統(tǒng)造成負(fù)擔(dān)。線程本身也要占用內(nèi)存空間,大量的線程會(huì)占用內(nèi)存資源并且可能會(huì)導(dǎo)致Out of Memory。即便沒有這樣的情況,大量的線程回收也會(huì)給GC帶來很大的壓力。
為了避免重復(fù)的創(chuàng)建線程,線程池的出現(xiàn)可以讓線程進(jìn)行復(fù)用。通俗點(diǎn)講,當(dāng)有工作來,就會(huì)向線程池拿一個(gè)線程,當(dāng)工作完成后,并不是直接關(guān)閉線程,而是將這個(gè)線程歸還給線程池供其他任務(wù)使用。
接下來從總體到細(xì)致的方式,來共同探討線程池。
二、總體的架構(gòu)來看Executor的框架圖:

接口:Executor,CompletionService,ExecutorService,ScheduledExecutorService
抽象類:AbstractExecutorService
實(shí)現(xiàn)類:ExecutorCompletionService,ThreadPoolExecutor,ScheduledThreadPoolExecutor
從圖中就可以看到主要的方法,本文主要討論的是ThreadPoolExecutor
三、研讀ThreadPoolExecutor看一下該類的構(gòu)造器:
public ThreadPoolExecutor(int paramInt1, int paramInt2, long paramLong, TimeUnit paramTimeUnit,BlockingQueue<Runnable> paramBlockingQueue, ThreadFactory paramThreadFactory,RejectedExecutionHandler paramRejectedExecutionHandler) { this.ctl = new AtomicInteger(ctlOf(-536870912, 0)); this.mainLock = new ReentrantLock(); this.workers = new HashSet(); this.termination = this.mainLock.newCondition(); if ((paramInt1 < 0) || (paramInt2 <= 0) || (paramInt2 < paramInt1) || (paramLong < 0L))throw new IllegalArgumentException(); if ((paramBlockingQueue == null) || (paramThreadFactory == null) || (paramRejectedExecutionHandler == null))throw new NullPointerException(); this.corePoolSize = paramInt1; this.maximumPoolSize = paramInt2; this.workQueue = paramBlockingQueue; this.keepAliveTime = paramTimeUnit.toNanos(paramLong); this.threadFactory = paramThreadFactory; this.handler = paramRejectedExecutionHandler;}
corePoolSize:線程池的核心池大小,在創(chuàng)建線程池之后,線程池默認(rèn)沒有任何線程。
當(dāng)有任務(wù)過來的時(shí)候才會(huì)去創(chuàng)建創(chuàng)建線程執(zhí)行任務(wù)。換個(gè)說法,線程池創(chuàng)建之后,線程池中的線程數(shù)為0,當(dāng)任務(wù)過來就會(huì)創(chuàng)建一個(gè)線程去執(zhí)行,直到線程數(shù)達(dá)到corePoolSize之后,就會(huì)被到達(dá)的任務(wù)放在隊(duì)列中。(注意是到達(dá)的任務(wù))。換句更精煉的話:corePoolSize表示允許線程池中允許同時(shí)運(yùn)行的最大線程數(shù)。
如果執(zhí)行了線程池的prestartAllCoreThreads()方法,線程池會(huì)提前創(chuàng)建并啟動(dòng)所有核心線程。
maximumPoolSize:線程池允許的最大線程數(shù),他表示最大能創(chuàng)建多少個(gè)線程。maximumPoolSize肯定是大于等于corePoolSize。
keepAliveTime:表示線程沒有任務(wù)時(shí)最多保持多久然后停止。默認(rèn)情況下,只有線程池中線程數(shù)大于corePoolSize時(shí),keepAliveTime才會(huì)起作用。換句話說,當(dāng)線程池中的線程數(shù)大于corePoolSize,并且一個(gè)線程空閑時(shí)間達(dá)到了keepAliveTime,那么就是shutdown。
Unit:keepAliveTime的單位。
workQueue:一個(gè)阻塞隊(duì)列,用來存儲(chǔ)等待執(zhí)行的任務(wù),當(dāng)線程池中的線程數(shù)超過它的corePoolSize的時(shí)候,線程會(huì)進(jìn)入阻塞隊(duì)列進(jìn)行阻塞等待。通過workQueue,線程池實(shí)現(xiàn)了阻塞功能
threadFactory:線程工廠,用來創(chuàng)建線程。
handler:表示當(dāng)拒絕處理任務(wù)時(shí)的策略。
3.1、任務(wù)緩存隊(duì)列在前面我們多次提到了任務(wù)緩存隊(duì)列,即workQueue,它用來存放等待執(zhí)行的任務(wù)。
workQueue的類型為BlockingQueue<Runnable>,通常可以取下面三種類型:
1)有界任務(wù)隊(duì)列ArrayBlockingQueue:基于數(shù)組的先進(jìn)先出隊(duì)列,此隊(duì)列創(chuàng)建時(shí)必須指定大小;
2)無界任務(wù)隊(duì)列LinkedBlockingQueue:基于鏈表的先進(jìn)先出隊(duì)列,如果創(chuàng)建時(shí)沒有指定此隊(duì)列大小,則默認(rèn)為Integer.MAX_VALUE;
3)直接提交隊(duì)列synchronousQueue:這個(gè)隊(duì)列比較特殊,它不會(huì)保存提交的任務(wù),而是將直接新建一個(gè)線程來執(zhí)行新來的任務(wù)。
3.2、拒絕策略AbortPolicy:丟棄任務(wù)并拋出RejectedExecutionException
CallerRunsPolicy:只要線程池未關(guān)閉,該策略直接在調(diào)用者線程中,運(yùn)行當(dāng)前被丟棄的任務(wù)。顯然這樣做不會(huì)真的丟棄任務(wù),但是,任務(wù)提交線程的性能極有可能會(huì)急劇下降。
DiscardOldestPolicy:丟棄隊(duì)列中最老的一個(gè)請(qǐng)求,也就是即將被執(zhí)行的一個(gè)任務(wù),并嘗試再次提交當(dāng)前任務(wù)。
DiscardPolicy:丟棄任務(wù),不做任何處理。
3.3、線程池的任務(wù)處理策略如果當(dāng)前線程池中的線程數(shù)目小于corePoolSize,則每來一個(gè)任務(wù),就會(huì)創(chuàng)建一個(gè)線程去執(zhí)行這個(gè)任務(wù);
如果當(dāng)前線程池中的線程數(shù)目>=corePoolSize,則每來一個(gè)任務(wù),會(huì)嘗試將其添加到任務(wù)緩存隊(duì)列當(dāng)中,若添加成功,則該任務(wù)會(huì)等待空閑線程將其取出去執(zhí)行;若添加失敗(一般來說是任務(wù)緩存隊(duì)列已滿),則會(huì)嘗試創(chuàng)建新的線程去執(zhí)行這個(gè)任務(wù);如果當(dāng)前線程池中的線程數(shù)目達(dá)到maximumPoolSize,則會(huì)采取任務(wù)拒絕策略進(jìn)行處理;
如果線程池中的線程數(shù)量大于 corePoolSize時(shí),如果某線程空閑時(shí)間超過keepAliveTime,線程將被終止,直至線程池中的線程數(shù)目不大于corePoolSize;如果允許為核心池中的線程設(shè)置存活時(shí)間,那么核心池中的線程空閑時(shí)間超過keepAliveTime,線程也會(huì)被終止。
3.4、線程池的關(guān)閉ThreadPoolExecutor提供了兩個(gè)方法,用于線程池的關(guān)閉,分別是shutdown()和shutdownNow(),其中:
shutdown():不會(huì)立即終止線程池,而是要等所有任務(wù)緩存隊(duì)列中的任務(wù)都執(zhí)行完后才終止,但再也不會(huì)接受新的任務(wù)
shutdownNow():立即終止線程池,并嘗試打斷正在執(zhí)行的任務(wù),并且清空任務(wù)緩存隊(duì)列,返回尚未執(zhí)行的任務(wù)
3.5、源碼分析首先來看最核心的execute方法,這個(gè)方法在AbstractExecutorService中并沒有實(shí)現(xiàn),從Executor接口,直到ThreadPoolExecutor才實(shí)現(xiàn)了改方法,
ExecutorService中的submit(),invokeAll(),invokeAny()都是調(diào)用的execute方法,所以execute是核心中的核心,源碼分析將圍繞它逐步展開。
public void execute(Runnable command) {if (command == null) throw new NullPointerException();/* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn’t, by returning false. * 如果正在運(yùn)行的線程數(shù)小于corePoolSize,那么將調(diào)用addWorker 方法來創(chuàng)建一個(gè)新的線程,并將該任務(wù)作為新線程的第一個(gè)任務(wù)來執(zhí)行。 當(dāng)然,在創(chuàng)建線程之前會(huì)做原子性質(zhì)的檢查,如果條件不允許,則不創(chuàng)建線程來執(zhí)行任務(wù),并返回false. * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * 如果一個(gè)任務(wù)成功進(jìn)入阻塞隊(duì)列,那么我們需要進(jìn)行一個(gè)雙重檢查來確保是我們已經(jīng)添加一個(gè)線程(因?yàn)榇嬖谥恍┚€程在上次檢查后他已經(jīng)死亡)或者 當(dāng)我們進(jìn)入該方法時(shí),該線程池已經(jīng)關(guān)閉。所以,我們將重新檢查狀態(tài),線程池關(guān)閉的情況下則回滾入隊(duì)列,線程池沒有線程的情況則創(chuàng)建一個(gè)新的線程。 * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. 如果任務(wù)無法入隊(duì)列(隊(duì)列滿了),那么我們將嘗試新開啟一個(gè)線程(從corepoolsize到擴(kuò)充到maximum),如果失敗了,那么可以確定原因,要么是 線程池關(guān)閉了或者飽和了(達(dá)到maximum),所以我們執(zhí)行拒絕策略。 */// 1.當(dāng)前線程數(shù)量小于corePoolSize,則創(chuàng)建并啟動(dòng)線程。int c = ctl.get();if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true))// 成功,則返回return; c = ctl.get();}// 2.步驟1失敗,則嘗試進(jìn)入阻塞隊(duì)列,if (isRunning(c) && workQueue.offer(command)) { // 入隊(duì)列成功,檢查線程池狀態(tài),如果狀態(tài)部署RUNNING而且remove成功,則拒絕任務(wù) int recheck = ctl.get(); if (! isRunning(recheck) && remove(command))reject(command); // 如果當(dāng)前worker數(shù)量為0,通過addWorker(null, false)創(chuàng)建一個(gè)線程,其任務(wù)為null else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 3. 步驟1和2失敗,則嘗試將線程池的數(shù)量有corePoolSize擴(kuò)充至maxPoolSize,如果失敗,則拒絕任務(wù)else if (!addWorker(command, false)) reject(command); }
相信看了代碼也是一臉懵,接下來用一個(gè)流程圖來講一講,他究竟干了什么事:
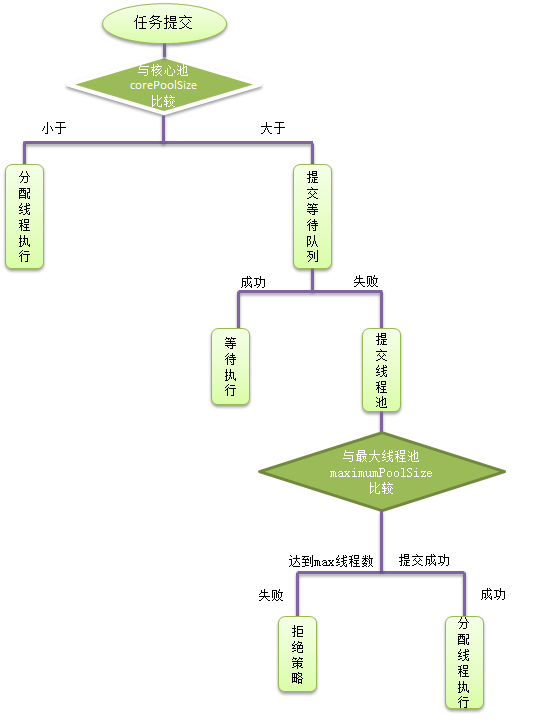
結(jié)合上面的流程圖來逐行解析,首先前面進(jìn)行空指針檢查,
wonrkerCountOf()方法能夠取得當(dāng)前線程池中的線程的總數(shù),取得當(dāng)前線程數(shù)與核心池大小比較,
如果小于,將通過addWorker()方法調(diào)度執(zhí)行。 如果大于核心池大小,那么就提交到等待隊(duì)列。 如果進(jìn)入等待隊(duì)列失敗,則會(huì)將任務(wù)直接提交給線程池。 如果線程數(shù)達(dá)到最大線程數(shù),那么就提交失敗,執(zhí)行拒絕策略。excute()方法中添加任務(wù)的方式是使用addWorker()方法,看一下源碼,一起學(xué)習(xí)一下。
private boolean addWorker(Runnable firstTask, boolean core) {retry: // 外層循環(huán),用于判斷線程池狀態(tài)for (;;) { int c = ctl.get(); int rs = runStateOf(c); // Check if queue empty only if necessary. if (rs >= SHUTDOWN &&! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))return false; // 內(nèi)層的循環(huán),任務(wù)是將worker數(shù)量加1 for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize)) return false;if (compareAndIncrementWorkerCount(c)) break retry;c = ctl.get(); // Re-read ctlif (runStateOf(c) != rs) continue retry;// else CAS failed due to workerCount change; retry inner loop }}// worker加1后,接下來將woker添加到HashSet<Worker>中,并啟動(dòng)workerboolean workerStarted = false;boolean workerAdded = false;Worker w = null;try { final ReentrantLock mainLock = this.mainLock; w = new Worker(firstTask); final Thread t = w.thread; if (t != null) {mainLock.lock();try { // Recheck while holding lock. // Back out on ThreadFactory failure or if // shut down before lock acquired. int c = ctl.get(); int rs = runStateOf(c); if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException();workers.add(w);int s = workers.size();if (s > largestPoolSize) largestPoolSize = s;workerAdded = true; }} finally { mainLock.unlock();} // 如果往HashSet<Worker>添加成功,則啟動(dòng)該線程if (workerAdded) { t.start(); workerStarted = true;} }} finally { if (! workerStarted)addWorkerFailed(w);}return workerStarted; }
addWorker(Runnable firstTask, boolean core)的主要任務(wù)是創(chuàng)建并啟動(dòng)線程。
他會(huì)根據(jù)當(dāng)前線程的狀態(tài)和給定的值(core or maximum)來判斷是否可以創(chuàng)建一個(gè)線程。
addWorker共有四種傳參方式。execute使用了其中三種,分別為:
1.addWorker(paramRunnable, true)
線程數(shù)小于corePoolSize時(shí),放一個(gè)需要處理的task進(jìn)Workers Set。如果Workers Set長(zhǎng)度超過corePoolSize,就返回false.
2.addWorker(null, false)
放入一個(gè)空的task進(jìn)workers Set,長(zhǎng)度限制是maximumPoolSize。這樣一個(gè)task為空的worker在線程執(zhí)行的時(shí)候會(huì)去任務(wù)隊(duì)列里拿任務(wù),這樣就相當(dāng)于創(chuàng)建了一個(gè)新的線程,只是沒有馬上分配任務(wù)。
3.addWorker(paramRunnable, false)
當(dāng)隊(duì)列被放滿時(shí),就嘗試將這個(gè)新來的task直接放入Workers Set,而此時(shí)Workers Set的長(zhǎng)度限制是maximumPoolSize。如果線程池也滿了的話就返回false.
還有一種情況是execute()方法沒有使用的
addWorker(null, true)
這個(gè)方法就是放一個(gè)null的task進(jìn)Workers Set,而且是在小于corePoolSize時(shí),如果此時(shí)Set中的數(shù)量已經(jīng)達(dá)到corePoolSize那就返回false,什么也不干。實(shí)際使用中是在prestartAllCoreThreads()方法,這個(gè)方法用來為線程池預(yù)先啟動(dòng)corePoolSize個(gè)worker等待從workQueue中獲取任務(wù)執(zhí)行。
執(zhí)行流程:
1、判斷線程池當(dāng)前是否為可以添加worker線程的狀態(tài),可以則繼續(xù)下一步,不可以return false:
A、線程池狀態(tài)>shutdown,可能為stop、tidying、terminated,不能添加worker線程
B、線程池狀態(tài)==shutdown,firstTask不為空,不能添加worker線程,因?yàn)閟hutdown狀態(tài)的線程池不接收新任務(wù)
C、線程池狀態(tài)==shutdown,firstTask==null,workQueue為空,不能添加worker線程,因?yàn)閒irstTask為空是為了添加一個(gè)沒有任務(wù)的線程再?gòu)膚orkQueue獲取task,而workQueue為空,說明添加無任務(wù)線程已經(jīng)沒有意義
2、線程池當(dāng)前線程數(shù)量是否超過上限(corePoolSize 或 maximumPoolSize),超過了return false,沒超過則對(duì)workerCount+1,繼續(xù)下一步
3、在線程池的ReentrantLock保證下,向Workers Set中添加新創(chuàng)建的worker實(shí)例,添加完成后解鎖,并啟動(dòng)worker線程,如果這一切都成功了,return true,如果添加worker入Set失敗或啟動(dòng)失敗,調(diào)用addWorkerFailed()邏輯
四、常見的四種線程池4.1、newFixedThreadPoolpublic static ExecutorService newFixedThreadPool(int var0) { return new ThreadPoolExecutor(var0, var0, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());}public static ExecutorService newFixedThreadPool(int var0, ThreadFactory var1) {return new ThreadPoolExecutor(var0, var0, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), var1);}
固定大小的線程池,可以指定線程池的大小,該線程池corePoolSize和maximumPoolSize相等,阻塞隊(duì)列使用的是LinkedBlockingQueue,大小為整數(shù)最大值。
該線程池中的線程數(shù)量始終不變,當(dāng)有新任務(wù)提交時(shí),線程池中有空閑線程則會(huì)立即執(zhí)行,如果沒有,則會(huì)暫存到阻塞隊(duì)列。對(duì)于固定大小的線程池,不存在線程數(shù)量的變化。同時(shí)使用無界的LinkedBlockingQueue來存放執(zhí)行的任務(wù)。當(dāng)任務(wù)提交十分頻繁的時(shí)候,LinkedBlockingQueue
迅速增大,存在著耗盡系統(tǒng)資源的問題。而且在線程池空閑時(shí),即線程池中沒有可運(yùn)行任務(wù)時(shí),它也不會(huì)釋放工作線程,還會(huì)占用一定的系統(tǒng)資源,需要shutdown。
4.2、newSingleThreadExecutorpublic static ExecutorService newSingleThreadExecutor() { return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()));}public static ExecutorService newSingleThreadExecutor(ThreadFactory var0) { return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), var0));}
單個(gè)線程線程池,只有一個(gè)線程的線程池,阻塞隊(duì)列使用的是LinkedBlockingQueue,若有多余的任務(wù)提交到線程池中,則會(huì)被暫存到阻塞隊(duì)列,待空閑時(shí)再去執(zhí)行。按照先入先出的順序執(zhí)行任務(wù)。
4.3、newCachedThreadPoolpublic static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue());}public static ExecutorService newCachedThreadPool(ThreadFactory var0) { return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue(), var0);}
緩存線程池,緩存的線程默認(rèn)存活60秒。線程的核心池corePoolSize大小為0,核心池最大為Integer.MAX_VALUE,阻塞隊(duì)列使用的是SynchronousQueue。是一個(gè)直接提交的阻塞隊(duì)列, 他總會(huì)迫使線程池增加新的線程去執(zhí)行新的任務(wù)。在沒有任務(wù)執(zhí)行時(shí),當(dāng)線程的空閑時(shí)間超過keepAliveTime(60秒),則工作線程將會(huì)終止被回收,當(dāng)提交新任務(wù)時(shí),如果沒有空閑線程,則創(chuàng)建新線程執(zhí)行任務(wù),會(huì)導(dǎo)致一定的系統(tǒng)開銷。如果同時(shí)又大量任務(wù)被提交,而且任務(wù)執(zhí)行的時(shí)間不是特別快,那么線程池便會(huì)新增出等量的線程池處理任務(wù),這很可能會(huì)很快耗盡系統(tǒng)的資源。
4.4、newScheduledThreadPoolpublic static ScheduledExecutorService newScheduledThreadPool(int var0) { return new ScheduledThreadPoolExecutor(var0);}public static ScheduledExecutorService newScheduledThreadPool(int var0, ThreadFactory var1) { return new ScheduledThreadPoolExecutor(var0, var1);}
定時(shí)線程池,該線程池可用于周期性地去執(zhí)行任務(wù),通常用于周期性的同步數(shù)據(jù)。
scheduleAtFixedRate:是以固定的頻率去執(zhí)行任務(wù),周期是指每次執(zhí)行任務(wù)成功執(zhí)行之間的間隔。
schedultWithFixedDelay:是以固定的延時(shí)去執(zhí)行任務(wù),延時(shí)是指上一次執(zhí)行成功之后和下一次開始執(zhí)行的之前的時(shí)間。
五、使用實(shí)例5.1、newFixedThreadPool實(shí)例public class FixPoolDemo { private static Runnable getThread(final int i) {return new Runnable() { @Override public void run() {try { Thread.sleep(500);} catch (InterruptedException e) { e.printStackTrace();}System.out.println(i); }}; } public static void main(String args[]) {ExecutorService fixPool = Executors.newFixedThreadPool(5);for (int i = 0; i < 10; i++) { fixPool.execute(getThread(i));}fixPool.shutdown(); }}5.2、newCachedThreadPool實(shí)例
public class CachePool { private static Runnable getThread(final int i){return new Runnable() { @Override public void run() {try { Thread.sleep(1000);}catch (Exception e){}System.out.println(i); }}; } public static void main(String args[]){ExecutorService cachePool = Executors.newCachedThreadPool();for (int i=1;i<=10;i++){ cachePool.execute(getThread(i));} }}
這里沒用調(diào)用shutDown方法,這里可以發(fā)現(xiàn)過60秒之后,會(huì)自動(dòng)釋放資源。
5.3、newSingleThreadExecutorpublic class SingPoolDemo { private static Runnable getThread(final int i){return new Runnable() { @Override public void run() {try { Thread.sleep(500);} catch (InterruptedException e) { e.printStackTrace();}System.out.println(i); }}; } public static void main(String args[]) throws InterruptedException {ExecutorService singPool = Executors.newSingleThreadExecutor();for (int i=0;i<10;i++){ singPool.execute(getThread(i));}singPool.shutdown(); }
這里需要注意一點(diǎn),newSingleThreadExecutor和newFixedThreadPool一樣,在線程池中沒有任務(wù)時(shí)可執(zhí)行,也不會(huì)釋放系統(tǒng)資源的,所以需要shudown。
5.4、newScheduledThreadPoolpublic class ScheduledExecutorServiceDemo { public static void main(String args[]) {ScheduledExecutorService ses = Executors.newScheduledThreadPool(10);ses.scheduleAtFixedRate(new Runnable() { @Override public void run() {try { Thread.sleep(4000); System.out.println(Thread.currentThread().getId() + '執(zhí)行了');} catch (InterruptedException e) { e.printStackTrace();} }}, 0, 2, TimeUnit.SECONDS); }}六、總結(jié)6.1、如何選擇線程池?cái)?shù)量
線程池的大小決定著系統(tǒng)的性能,過大或者過小的線程池?cái)?shù)量都無法發(fā)揮最優(yōu)的系統(tǒng)性能。
當(dāng)然線程池的大小也不需要做的太過于精確,只需要避免過大和過小的情況。一般來說,確定線程池的大小需要考慮CPU的數(shù)量,內(nèi)存大小,任務(wù)是計(jì)算密集型還是IO密集型等因素
NCPU = CPU的數(shù)量
UCPU = 期望對(duì)CPU的使用率 0 ≤ UCPU ≤ 1
W/C = 等待時(shí)間與計(jì)算時(shí)間的比率
如果希望處理器達(dá)到理想的使用率,那么線程池的最優(yōu)大小為:
線程池大小=NCPU *UCPU(1+W/C)
在Java中使用
int ncpus = Runtime.getRuntime().availableProcessors();
獲取CPU的數(shù)量。
6.2、線程池工廠Executors的線程池如果不指定線程工廠會(huì)使用Executors中的DefaultThreadFactory,默認(rèn)線程池工廠創(chuàng)建的線程都是非守護(hù)線程。
使用自定義的線程工廠可以做很多事情,比如可以跟蹤線程池在何時(shí)創(chuàng)建了多少線程,也可以自定義線程名稱和優(yōu)先級(jí)。如果將
新建的線程都設(shè)置成守護(hù)線程,當(dāng)主線程退出后,將會(huì)強(qiáng)制銷毀線程池。
下面這個(gè)例子,記錄了線程的創(chuàng)建,并將所有的線程設(shè)置成守護(hù)線程。
public class ThreadFactoryDemo { public static class MyTask1 implements Runnable{@Overridepublic void run() { System.out.println(System.currentTimeMillis()+'Thrad ID:'+Thread.currentThread().getId()); try {Thread.sleep(100); } catch (InterruptedException e) {e.printStackTrace(); }} } public static void main(String[] args){ MyTask1 task = new MyTask1();ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MICROSECONDS, new SynchronousQueue<Runnable>(), new ThreadFactory() { @Override public Thread newThread(Runnable r) {Thread t = new Thread(r);t.setDaemon(true);System.out.println('創(chuàng)建線程'+t);return t; }});for (int i = 0;i<=4;i++){ es.submit(task);} }}6.3、擴(kuò)展線程池
ThreadPoolExecutor是可以拓展的,它提供了幾個(gè)可以在子類中改寫的方法:beforeExecute,afterExecute和terimated。
在執(zhí)行任務(wù)的線程中將調(diào)用beforeExecute和afterExecute,這些方法中還可以添加日志,計(jì)時(shí),監(jiān)視或統(tǒng)計(jì)收集的功能,
還可以用來輸出有用的調(diào)試信息,幫助系統(tǒng)診斷故障。下面是一個(gè)擴(kuò)展線程池的例子:
public class ThreadFactoryDemo { public static class MyTask1 implements Runnable{@Overridepublic void run() { System.out.println(System.currentTimeMillis()+'Thrad ID:'+Thread.currentThread().getId()); try {Thread.sleep(100); } catch (InterruptedException e) {e.printStackTrace(); }} } public static void main(String[] args){ MyTask1 task = new MyTask1();ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MICROSECONDS, new SynchronousQueue<Runnable>(), new ThreadFactory() { @Override public Thread newThread(Runnable r) {Thread t = new Thread(r);t.setDaemon(true);System.out.println('創(chuàng)建線程'+t);return t; }});for (int i = 0;i<=4;i++){ es.submit(task);} }}6.4、線程池的正確使用
以下阿里編碼規(guī)范里面說的一段話:
線程池不允許使用Executors去創(chuàng)建,而是通過ThreadPoolExecutor的方式,這樣的處理方式讓寫的同學(xué)更加明確線程池的運(yùn)行規(guī)則,規(guī)避資源耗盡的風(fēng)險(xiǎn)。 說明:Executors各個(gè)方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:主要問題是堆積的請(qǐng)求處理隊(duì)列可能會(huì)耗費(fèi)非常大的內(nèi)存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:主要問題是線程數(shù)最大數(shù)是Integer.MAX_VALUE,可能會(huì)創(chuàng)建數(shù)量非常多的線程,甚至OOM。
七、手動(dòng)創(chuàng)建線程池有幾個(gè)注意點(diǎn)7.1、任務(wù)獨(dú)立如何任務(wù)依賴于其他任務(wù),那么可能產(chǎn)生死鎖。例如某個(gè)任務(wù)等待另一個(gè)任務(wù)的返回值或執(zhí)行結(jié)果,那么除非線程池足夠大,否則將發(fā)生線程饑餓死鎖。
7.2、合理配置阻塞時(shí)間過長(zhǎng)的任務(wù)如果任務(wù)阻塞時(shí)間過長(zhǎng),那么即使不出現(xiàn)死鎖,線程池的性能也會(huì)變得很糟糕。在Java并發(fā)包里可阻塞方法都同時(shí)定義了限時(shí)方式和不限時(shí)方式。例如
Thread.join,BlockingQueue.put,CountDownLatch.await等,如果任務(wù)超時(shí),則標(biāo)識(shí)任務(wù)失敗,然后中止任務(wù)或者將任務(wù)放回隊(duì)列以便隨后執(zhí)行,這樣,無論任務(wù)的最終結(jié)果是否成功,這種辦法都能夠保證任務(wù)總能繼續(xù)執(zhí)行下去。
7.3、設(shè)置合理的線程池大小只需要避免過大或者過小的情況即可,上文的公式線程池大小=NCPU *UCPU(1+W/C)。
7.4、選擇合適的阻塞隊(duì)列newFixedThreadPool和newSingleThreadExecutor都使用了無界的阻塞隊(duì)列,無界阻塞隊(duì)列會(huì)有消耗很大的內(nèi)存,如果使用了有界阻塞隊(duì)列,它會(huì)規(guī)避內(nèi)存占用過大的問題,但是當(dāng)任務(wù)填滿有界阻塞隊(duì)列,新的任務(wù)該怎么辦?在使用有界隊(duì)列是,需要選擇合適的拒絕策略,隊(duì)列的大小和線程池的大小必須一起調(diào)節(jié)。對(duì)于非常大的或者無界的線程池,可以使用SynchronousQueue來避免任務(wù)排隊(duì),以直接將任務(wù)從生產(chǎn)者提交到工作者線程。
下面是Thrift框架處理socket任務(wù)所使用的一個(gè)線程池,可以看一下FaceBook的工程師是如何自定義線程池的。
private static ExecutorService createDefaultExecutorService(Args args) { SynchronousQueue executorQueue = new SynchronousQueue(); return new ThreadPoolExecutor(args.minWorkerThreads, args.maxWorkerThreads, 60L, TimeUnit.SECONDS, executorQueue);}
以上就是如何理解Java線程池及其使用方法的詳細(xì)內(nèi)容,更多關(guān)于Java線程池的資料請(qǐng)關(guān)注好吧啦網(wǎng)其它相關(guān)文章!
相關(guān)文章:
1. 如何通過vscode運(yùn)行調(diào)試javascript代碼2. HTML <!DOCTYPE> 標(biāo)簽3. JSP+Servlet實(shí)現(xiàn)文件上傳到服務(wù)器功能4. JavaScript與JQuery框架基礎(chǔ)入門教程5. ajax post下載flask文件流以及中文文件名問題6. ASP.NET泛型三之使用協(xié)變和逆變實(shí)現(xiàn)類型轉(zhuǎn)換7. WML語(yǔ)言的基本情況8. 利用CSS制作3D動(dòng)畫9. 利用CSS3新特性創(chuàng)建透明邊框三角10. ASP中解決“對(duì)象關(guān)閉時(shí),不允許操作。”的詭異問題……

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備