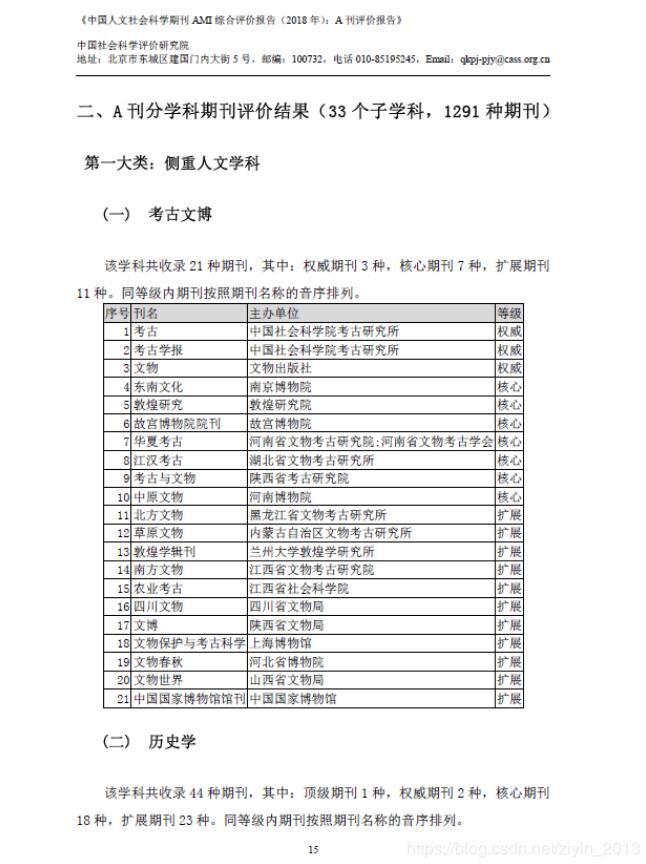
python實(shí)現(xiàn)PDF中表格轉(zhuǎn)化為Excel的方法
這幾天想統(tǒng)計(jì)一下《中國人文社會(huì)科學(xué)期刊 AMI 綜合評價(jià)報(bào)告(2018 年):A 刊評價(jià)報(bào)告》中的期刊,但是只找到了該報(bào)告的PDF版,對于表格的編輯不太方便,于是想到用Python將表格轉(zhuǎn)成Excel格式。
看過別人寫的博客,發(fā)現(xiàn)Python解析PDF有以下四種方式:
-pdfminer:擅長文字的解析,把表格解析成普通的文本,沒有格式;-pdf2html:把pdf解析成html,但html的標(biāo)簽并沒有規(guī)律,解析一個(gè)表格還可以,多個(gè)表格的話不太好提取;-tabula:對于簡單的表格,即單元格中沒有換行的,表頭表尾形式不復(fù)雜的,使用比較方便。但是單腦需要Java環(huán)境;-pdfplumber:是一個(gè)可以處理pdf格式信息的庫。可以查找關(guān)于每個(gè)文本字符、矩陣、和行的詳細(xì)信息,也可以對表格進(jìn)行提取并進(jìn)行可視化調(diào)試。
本文采用pdfplumber庫讀取PDF中的表格,運(yùn)行環(huán)境:Python3.5.2,Anaconda4.2.0。首先簡單介紹一下pdfplumber庫:
-pdfplumber.pdf中包含了.metadata和.pages兩個(gè)屬性:.metadata是一個(gè)包含pdf信息的字典。.pages是一個(gè)包含頁面信息的列表。
-pdfplumber.page的類中包含的主要的屬性:
.page_number 頁碼。.width 頁面寬度。.height 頁面高度。.objects/.chars/.lines/.rects 這些屬性中每一個(gè)都是一個(gè)列表,每個(gè)列表都包含一個(gè)字典,每個(gè)字典用于說明頁面中的對象信息, 包括直線,字符, 方格等位置信息。
-一些常用的方法:
.extract_text() 用來提頁面中的文本,將頁面的所有字符對象整理為的那個(gè)字符串。.extract_words() 返回的是所有的單詞及其相關(guān)信息。.extract_tables() 提取頁面的表格。.to_image() 用于可視化調(diào)試時(shí),返回PageImage類的一個(gè)實(shí)例。
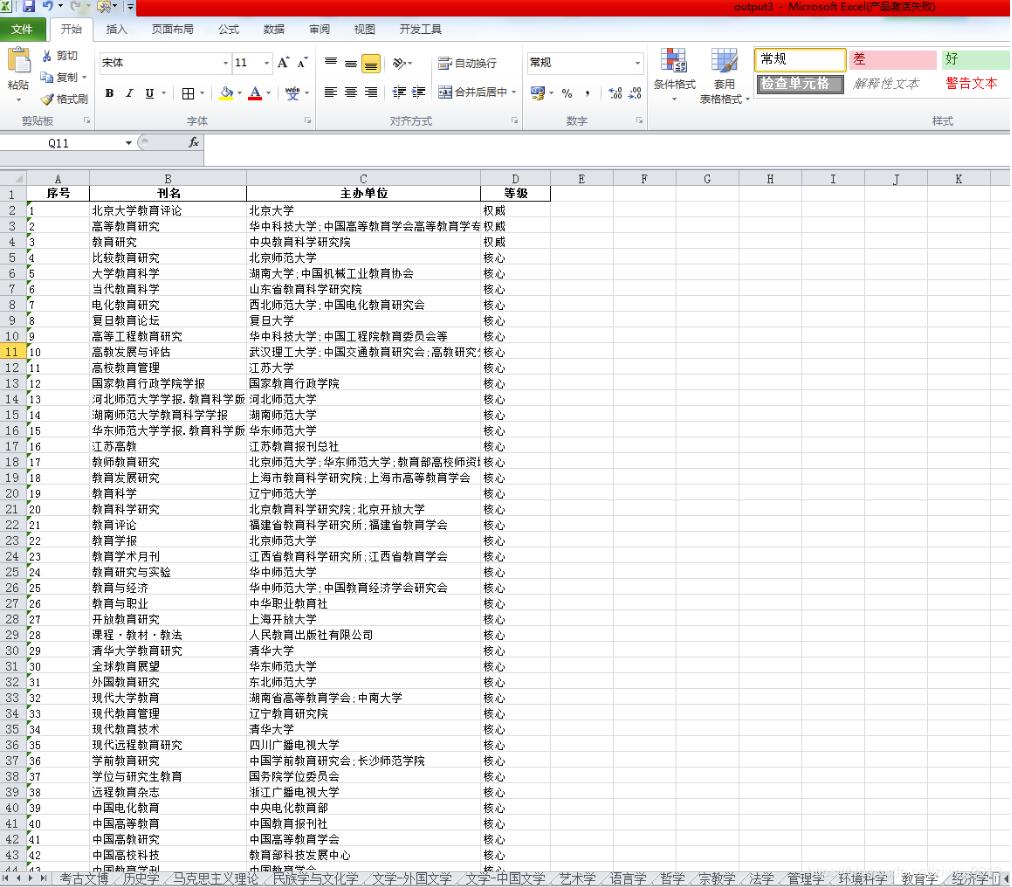
import pdfplumberimport pandas as pdpath = ’test.pdf’pdf = pdfplumber.open(path)i=1#writer=pd.ExcelWriter(’output.xlsx’)df=pd.DataFrame(columns=[’序號’,’刊名’,’主辦單位’,’等級’])sheetname=[’考古文博’,’歷史學(xué)’,’馬克思主義理論’,’民族學(xué)與文化學(xué)’,’文學(xué)-外國文學(xué)’,’文學(xué)-中國文學(xué)’,’藝術(shù)學(xué)’,’語言學(xué)’,’哲學(xué)’,’宗教學(xué)’,’法學(xué)’ ,’管理學(xué)’,’環(huán)境科學(xué)’,’教育學(xué)’,’經(jīng)濟(jì)學(xué)-財(cái)政科學(xué)’,’經(jīng)濟(jì)學(xué)-工業(yè)經(jīng)濟(jì)’,’經(jīng)濟(jì)學(xué)-金融’,’經(jīng)濟(jì)學(xué)-經(jīng)濟(jì)管理’,’經(jīng)濟(jì)學(xué)-經(jīng)濟(jì)綜合’,’經(jīng)濟(jì)學(xué)-貿(mào)易經(jīng)濟(jì)’ ,’經(jīng)濟(jì)學(xué)-農(nóng)業(yè)經(jīng)濟(jì)’,’經(jīng)濟(jì)學(xué)-世界經(jīng)濟(jì)’,’人文地理學(xué)’,’社會(huì)學(xué)’,’體育學(xué)’,’統(tǒng)計(jì)學(xué)’,’圖書館情報(bào)與檔案學(xué)’,’心理學(xué)’,’新聞學(xué)與傳播學(xué)’ ,’政治學(xué)-國際政治’,’政治學(xué)-中國政治’,’綜合-高校綜合性學(xué)報(bào)’,’綜合-綜合性人文社科期刊’] ##由于存在一個(gè)表格跨頁的情況,先將所有表格存放在一個(gè)DataFrame中,再根據(jù)序號拆分。for page in pdf.pages[17:59]: print (page) # 獲取當(dāng)前頁面的全部文本信息,包括表格中的文字 # print(page.extract_text()) for table in page.extract_tables(): #print(table) df=df.append(pd.DataFrame(table[1:],columns=table[0]),ignore_index=True)print (df)writer=pd.ExcelWriter(’output3.xlsx’)new_df=pd.DataFrame()j=1index=[]#記錄序號==1的行索引,用于后面的表格拆分for i in range(len(df)): if df.ix[i,0]==’1’: index.append(i) print ('################')index.append(len(df))#print (index)#按行索引將內(nèi)容切片并逐個(gè)添加到表中for t in range(len(index)-1): new_df=df.ix[index[t]:index[t+1]-1,:] #print (new_df) new_df.to_excel(writer,sheet_name=sheetname[t],encoding=’gb2312’,index=None)writer.save()pdf.close()print(’finished’)
最終保存為Excel。
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. 低版本IE正常運(yùn)行HTML5+CSS3網(wǎng)站的3種解決方案2. 利用CSS制作3D動(dòng)畫3. 讀大數(shù)據(jù)量的XML文件的讀取問題4. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁的方法5. html5手機(jī)觸屏touch事件介紹6. 用xslt+css讓RSS顯示的跟網(wǎng)頁一樣漂亮7. 《CSS3實(shí)戰(zhàn)》筆記--漸變設(shè)計(jì)(一)8. 測試模式 - XSL教程 - 59. CSS3實(shí)現(xiàn)動(dòng)態(tài)翻牌效果 仿百度貼吧3D翻牌一次動(dòng)畫特效10. xpath簡介_動(dòng)力節(jié)點(diǎn)Java學(xué)院整理
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備