對(duì)python中l(wèi)ist的五種查找方法說(shuō)明
Python中是有查找功能的,五種方式:in、not in、count、index,find 前兩種方法是保留字,后兩種方式是列表的方法。
下面以a_list = [’a’,’b’,’c’,’hello’],為例作介紹:
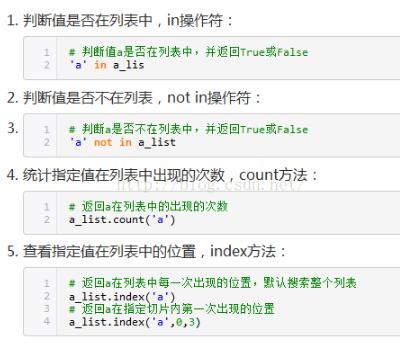
string類(lèi)型的話(huà)可用find方法去查找字符串位置:
a_list.find(’a’)
如果找到則返回第一個(gè)匹配的位置,如果沒(méi)找到則返回-1,而如果通過(guò)index方法去查找的話(huà),沒(méi)找到的話(huà)會(huì)報(bào)錯(cuò)。
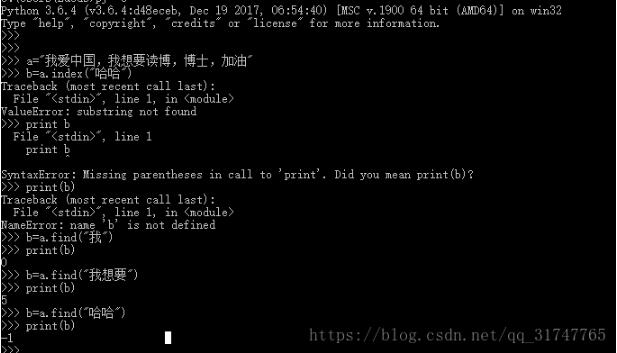
補(bǔ)充知識(shí):Python中查找包含它的列表元素的索引,index報(bào)錯(cuò)!!!
對(duì)于列表['foo', 'bar', 'baz']和列表中的項(xiàng)目'bar',如何在Python中獲取其索引(1)?
一、index
>>> ['foo', 'bar', 'baz'].index('bar')
警告如下
請(qǐng)注意,雖然這也許是回答這個(gè)問(wèn)題最徹底的方法是問(wèn),index是一個(gè)相當(dāng)薄弱的組件listAPI,而我不記得我最后一次使用它的憤怒。在評(píng)論中已經(jīng)向我指出,因?yàn)檫@個(gè)答案被大量引用,所以應(yīng)該更加完整。關(guān)于list.index跟隨的一些警告。最初可能需要查看文檔字符串:
>>> print(list.index.__doc__)L.index(value, [start, [stop]]) -> integer -- return first index of value.Raises ValueError if the value is not present.
我曾經(jīng)使用過(guò)的大多數(shù)地方index,我現(xiàn)在使用列表推導(dǎo)或生成器表達(dá)式,因?yàn)樗鼈兏哂型茝V性。因此,如果您正在考慮使用index,請(qǐng)查看這些出色的python功能。
如果元素不在列表中,則拋出
如果項(xiàng)目不存在則調(diào)用index結(jié)果ValueError。
>>> [1, 1].index(2)Traceback (most recent call last): File '<stdin>', line 1, in <module>ValueError: 2 is not in list
如果該項(xiàng)目可能不在列表中,您應(yīng)該
首先檢查它item in my_list(干凈,可讀的方法),或
將index呼叫包裹在try/except捕獲的塊中ValueError(可能更快,至少當(dāng)搜索列表很長(zhǎng)時(shí),該項(xiàng)通常存在。)
二、enumerate()
大多數(shù)答案解釋了如何查找單個(gè)索引,但如果項(xiàng)目在列表中多次,則它們的方法不會(huì)返回多個(gè)索引。用途enumerate():
for i, j in enumerate([’foo’, ’bar’, ’baz’]): if j == ’bar’: print(i)
該index()函數(shù)僅返回第一個(gè)匹配項(xiàng),同時(shí)enumerate()返回所有匹配項(xiàng)。
作為列表理解:
[i for i, j in enumerate([’foo’, ’bar’, ’baz’]) if j == ’bar’]
這里還有另一個(gè)小解決方案itertools.count()(與枚舉幾乎相同):
from itertools import izip as zip, count # izip for maximum efficiency
[i for i, j in zip(count(), [’foo’, ’bar’, ’baz’]) if j == ’bar’]
對(duì)于較大的列表,這比使用更有效enumerate():
$ python -m timeit -s 'from itertools import izip as zip, count' '[i for i, j in zip(count(), [’foo’, ’bar’, ’baz’]*500) if j == ’bar’]'10000 loops, best of 3: 174 usec per loop$ python -m timeit '[i for i, j in enumerate([’foo’, ’bar’, ’baz’]*500) if j == ’bar’]'10000 loops, best of 3: 196 usec per loop
三、NumPy
如果您想要所有索引,那么您可以使用NumPy:
import numpy as np array = [1, 2, 1, 3, 4, 5, 1]item = 1np_array = np.array(array)item_index = np.where(np_array==item)print item_index# Out: (array([0, 2, 6], dtype=int64),)
它是清晰易讀的解決方案。
四、zip
具有該zip功能的所有索引:
get_indexes = lambda x, xs: [i for (y, i) in zip(xs, range(len(xs))) if x == y] print get_indexes(2, [1, 2, 3, 4, 5, 6, 3, 2, 3, 2])print get_indexes(’f’, ’xsfhhttytffsafweef’)
以上這篇對(duì)python中l(wèi)ist的五種查找方法說(shuō)明就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:
1. IDEA Maven項(xiàng)目使用debug模式運(yùn)行Tomcat的詳細(xì)教程2. spring boot動(dòng)態(tài)切換數(shù)據(jù)源的實(shí)現(xiàn)3. python 繪制斜率圖進(jìn)行對(duì)比分析4. Android實(shí)現(xiàn)儀表盤(pán)控件開(kāi)發(fā)5. python GUI模擬實(shí)現(xiàn)計(jì)算器6. 利用python+ffmpeg合并B站視頻及格式轉(zhuǎn)換的實(shí)例代碼7. Android自定義短信倒計(jì)時(shí)view流程分析8. idea2020.1最新版永久破解/pycharm也可用(步驟詳解)9. IDEA中解決 git pull 沖突的方法10. IDEA下lombok安裝及找不到get,set的問(wèn)題的解決方法

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備