Python調(diào)用百度OCR實(shí)現(xiàn)圖片文字識(shí)別的示例代碼
百度AI提供了一天50000次的免費(fèi)文字識(shí)別額度,可以愉快的免費(fèi)使用!下面直接上方法:
首先在百度AI創(chuàng)建一個(gè)應(yīng)用,按照下圖創(chuàng)建即可,創(chuàng)建后會(huì)獲得如下:
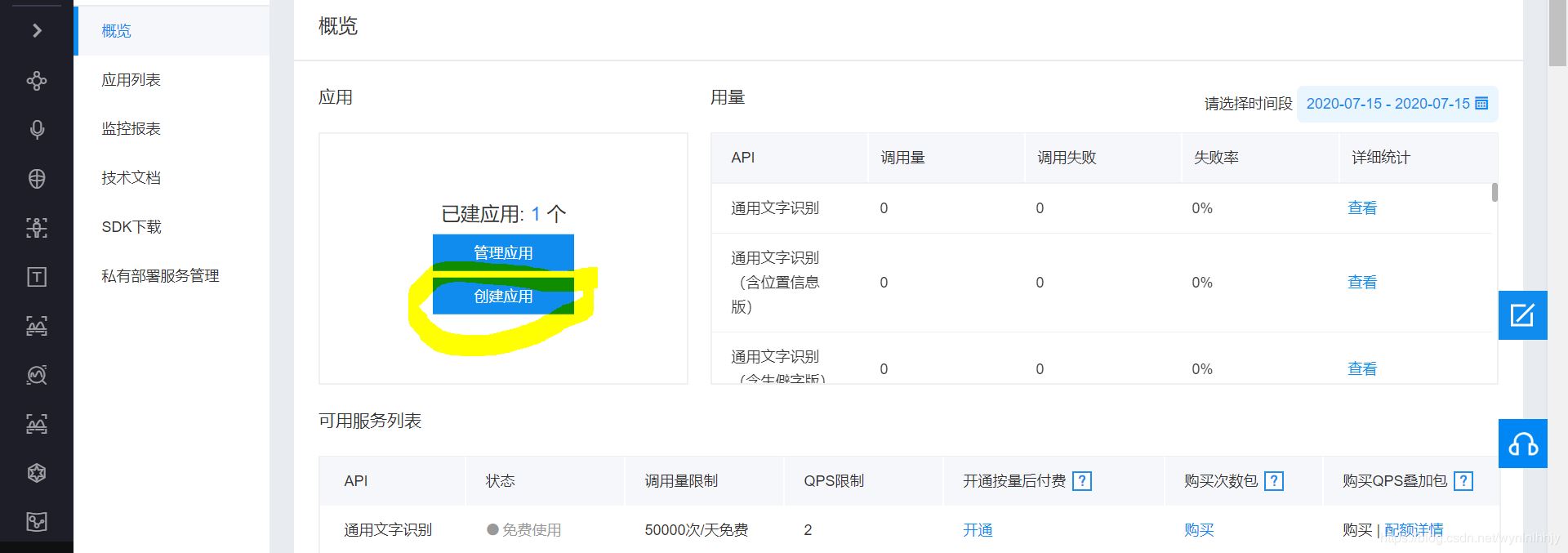
創(chuàng)建后會(huì)獲得如下信息:
APP_ID = ’******’API_KEY = ’************’SECRET_KEY = ’**************’
下面就是百度API包的安裝,在終端cmd輸入如下語句直接pip方式安裝,注意是 baidu-api 哦!
pip install --user baidu-aip
接下來上python代碼,圖片修改為你的圖片就可以直接運(yùn)行了:
from aip import AipOcr # 定義常量APP_ID = ’21372704’API_KEY = ’YKpXQwN5zj79g99fZK8i4Kn1’SECRET_KEY = ’RTIAaFrvvgHbej7eALMKmjR0uF93rHCQ’ # 初始化AipFace對(duì)象aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY) # 讀取圖片filePath = 'test.JPG' def get_file_content(filePath): with open(filePath, ’rb’) as fp: return fp.read() # 定義參數(shù)變量options = { ’detect_direction’: ’true’, ’language_type’: ’CHN_ENG’,} # 調(diào)用通用文字識(shí)別接口result = aipOcr.basicGeneral(get_file_content(filePath), options)print(result)words_result=result[’words_result’]for i in range(len(words_result)): print(words_result[i][’words’]) #代碼參考了:https://blog.csdn.net/u013421629/article/details/79500336
圖片不咋清晰就會(huì)出現(xiàn)識(shí)別出來不太準(zhǔn)確的現(xiàn)象,但是對(duì)比pytesseract的OCR結(jié)果已經(jīng)好了非常多,百度OCR識(shí)別出來原始的是字典格式。下面上例子:



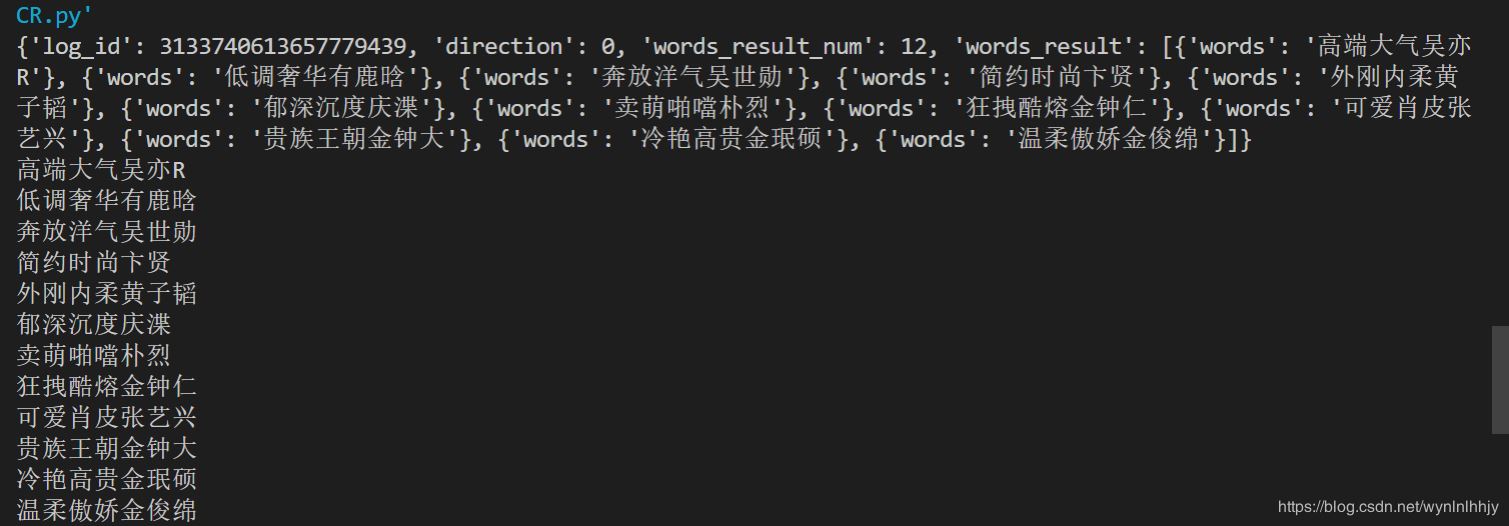
到此這篇關(guān)于Python調(diào)用百度OCR實(shí)現(xiàn)圖片文字識(shí)別的示例代碼的文章就介紹到這了,更多相關(guān)Python 圖片文字識(shí)別內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備