python使用Word2Vec進(jìn)行情感分析解析
python實(shí)現(xiàn)情感分析(Word2Vec)
** 前幾天跟著老師做了幾個(gè)項(xiàng)目,老師寫的時(shí)候劈里啪啦一頓敲,寫了個(gè)啥咱也布吉島,線下自己就瞎琢磨,終于實(shí)現(xiàn)了一個(gè)最簡(jiǎn)單的項(xiàng)目。輸入文本,然后分析情感,判斷出是好感還是反感。看最終結(jié)果:↓↓↓↓↓↓
1
 2
2
大概就是這樣,接下來(lái)實(shí)現(xiàn)一下。
實(shí)現(xiàn)步驟
加載數(shù)據(jù),預(yù)處理
數(shù)據(jù)就是正反兩類,保存在neg.xls和pos.xls文件中,

數(shù)據(jù)內(nèi)容類似購(gòu)物網(wǎng)站的評(píng)論,分別有一萬(wàn)多個(gè)好評(píng)和一萬(wàn)多個(gè)差評(píng),通過(guò)對(duì)它們的處理,變成我們用來(lái)訓(xùn)練模型的特征和標(biāo)記。
首先導(dǎo)入幾個(gè)python常見的庫(kù),train_test_split用來(lái)對(duì)特征向量的劃分,numpy和pands是處理數(shù)據(jù)常見的庫(kù),jieba庫(kù)用來(lái)分詞,joblib用來(lái)保存訓(xùn)練好的模型,sklearn.svm是機(jī)器學(xué)習(xí)訓(xùn)練模型常用的庫(kù),我覺得核心的就是Word2Vec這個(gè)庫(kù)了,作用就是將自然語(yǔ)言中的字詞轉(zhuǎn)為計(jì)算機(jī)可以理解的稠密向量。
from sklearn.model_selection import train_test_splitimport numpy as npimport pandas as pdimport jieba as jbfrom sklearn.externals import joblibfrom sklearn.svm import SVCfrom gensim.models.word2vec import Word2Vec
加載數(shù)據(jù),將數(shù)據(jù)分詞,將正反樣本拼接,然后創(chuàng)建全是0和全是1的向量拼接起來(lái)作為標(biāo)簽,
neg =pd.read_excel('data/neg.xls',header=None,index=None) pos =pd.read_excel('data/pos.xls',header=None,index=None) # 這是兩類數(shù)據(jù)都是x值 pos[’words’] = pos[0].apply(lambda x:list(jb.cut(x))) neg[’words’] = neg[0].apply(lambda x:list(jb.cut(x))) #需要y值 0 代表neg 1代表是pos y = np.concatenate((np.ones(len(pos)),np.zeros(len(neg)))) X = np.concatenate((pos[’words’],neg[’words’]))
切分訓(xùn)練集和測(cè)試集
利用train_test_split函數(shù)切分訓(xùn)練集和測(cè)試集,test_size表示切分的比例,百分之二十用來(lái)測(cè)試,這里的random_state是隨機(jī)種子數(shù),為了保證程序每次運(yùn)行都分割一樣的訓(xùn)練集和測(cè)試集。否則,同樣的算法模型在不同的訓(xùn)練集和測(cè)試集上的效果不一樣。訓(xùn)練集和測(cè)試集的標(biāo)簽無(wú)非就是0和1,直接保存,接下來(lái)單獨(dú)處理特征向量。
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=3) #保存數(shù)據(jù) np.save('data/y_train.npy',y_train) np.save('data/y_test.npy',y_test)
詞向量計(jì)算
網(wǎng)上搜到的專業(yè)解釋是這樣說(shuō)的:使用一層神經(jīng)網(wǎng)絡(luò)將one-hot(獨(dú)熱編碼)形式的詞向量映射到分布式形式的詞向量。使用了Hierarchical softmax, negative sampling等技巧進(jìn)行訓(xùn)練速度上的優(yōu)化。作用:我們?nèi)粘I钪惺褂玫淖匀徽Z(yǔ)言不能夠直接被計(jì)算機(jī)所理解,當(dāng)我們需要對(duì)這些自然語(yǔ)言進(jìn)行處理時(shí),就需要使用特定的手段對(duì)其進(jìn)行分析或預(yù)處理。使用one-hot編碼形式對(duì)文字進(jìn)行處理可以得到詞向量,但是,由于對(duì)文字進(jìn)行唯一編號(hào)進(jìn)行分析的方式存在數(shù)據(jù)稀疏的問(wèn)題,Word2Vec能夠解決這一問(wèn)題,實(shí)現(xiàn)word embedding專業(yè)解釋的話我還是一臉懵,后來(lái)看了一個(gè)栗子,大概是這樣:word2vec也叫word embeddings,中文名“詞向量”,作用就是將自然語(yǔ)言中的字詞轉(zhuǎn)為計(jì)算機(jī)可以理解的稠密向量(Dense Vector)。在word2vec出現(xiàn)之前,自然語(yǔ)言處理經(jīng)常把字詞轉(zhuǎn)為離散的單獨(dú)的符號(hào),也就是One-Hot Encoder。

在語(yǔ)料庫(kù)中,杭州、上海、寧波、北京各對(duì)應(yīng)一個(gè)向量,向量中只有一個(gè)值為1,其余都為0。但是使用One-Hot Encoder有以下問(wèn)題。一方面,城市編碼是隨機(jī)的,向量之間相互獨(dú)立,看不出城市之間可能存在的關(guān)聯(lián)關(guān)系。其次,向量維度的大小取決于語(yǔ)料庫(kù)中字詞的多少。如果將世界所有城市名稱對(duì)應(yīng)的向量合為一個(gè)矩陣的話,那這個(gè)矩陣過(guò)于稀疏,并且會(huì)造成維度災(zāi)難。使用Vector Representations可以有效解決這個(gè)問(wèn)題。Word2Vec可以將One-Hot Encoder轉(zhuǎn)化為低維度的連續(xù)值,也就是稠密向量,并且其中意思相近的詞將被映射到向量空間中相近的位置。如果將embed后的城市向量通過(guò)PCA降維后可視化展示出來(lái),那就是這個(gè)樣子。

計(jì)算詞向量
#初始化模型和詞表 wv = Word2Vec(size=300,min_count=10) wv.build_vocab(x_train) # 訓(xùn)練并建模 wv.train(x_train,total_examples=1, epochs=1) #獲取train_vecs train_vecs = np.concatenate([ build_vector(z,300,wv) for z in x_train]) #保存處理后的詞向量 np.save(’data/train_vecs.npy’,train_vecs) #保存模型 wv.save('data/model3.pkl') wv.train(x_test,total_examples=1, epochs=1) test_vecs = np.concatenate([build_vector(z,300,wv) for z in x_test]) np.save(’data/test_vecs.npy’,test_vecs)
•對(duì)句子中的所有詞向量取均值,來(lái)生成一個(gè)句子的vec
def build_vector(text,size,wv): #創(chuàng)建一個(gè)指定大小的數(shù)據(jù)空間 vec = np.zeros(size).reshape((1,size)) #count是統(tǒng)計(jì)有多少詞向量 count = 0 #循環(huán)所有的詞向量進(jìn)行求和 for w in text: try: vec += wv[w].reshape((1,size)) count +=1 except: continue #循環(huán)完成后求均值 if count!=0: vec/=count return vec
訓(xùn)練SVM模型
訓(xùn)練就用SVM,sklearn庫(kù)已經(jīng)封裝了具體的算法,只需要調(diào)用就行了,原理也挺麻煩,老師講課的時(shí)候我基本都在睡覺,這兒就不裝嗶了。(想裝裝不出來(lái)。。😭)
#創(chuàng)建SVC模型 cls = SVC(kernel='rbf',verbose=True) #訓(xùn)練模型 cls.fit(train_vecs,y_train) #保存模型 joblib.dump(cls,'data/svcmodel.pkl') #輸出評(píng)分 print(cls.score(test_vecs,y_test))
預(yù)測(cè)
訓(xùn)練完后也得到了訓(xùn)練好的模型,基本這個(gè)項(xiàng)目已經(jīng)完成了,然后為了使看起來(lái)好看,加了個(gè)圖形用戶界面,看起來(lái)有點(diǎn)逼格,
from tkinter import *import numpy as npimport jieba as jbimport joblibfrom gensim.models.word2vec import Word2Vecclass core(): def __init__(self,str): self.string=str def build_vector(self,text,size,wv): #創(chuàng)建一個(gè)指定大小的數(shù)據(jù)空間 vec = np.zeros(size).reshape((1,size)) #count是統(tǒng)計(jì)有多少詞向量 count = 0 #循環(huán)所有的詞向量進(jìn)行求和 for w in text: try: vec += wv[w].reshape((1,size)) count +=1 except: continue #循環(huán)完成后求均值 if count!=0: vec/=count return vec def get_predict_vecs(self,words): # 加載模型 wv = Word2Vec.load('data/model3.pkl') #將新的詞轉(zhuǎn)換為向量 train_vecs = self.build_vector(words,300,wv) return train_vecs def svm_predict(self,string): # 對(duì)語(yǔ)句進(jìn)行分詞 words = jb.cut(string) # 將分詞結(jié)果轉(zhuǎn)換為詞向量 word_vecs = self.get_predict_vecs(words) #加載模型 cls = joblib.load('data/svcmodel.pkl') #預(yù)測(cè)得到結(jié)果 result = cls.predict(word_vecs) #輸出結(jié)果 if result[0]==1: return '好感' else: return '反感' def main(self): s=self.svm_predict(self.string) return sroot=Tk()root.title('情感分析')sw = root.winfo_screenwidth()#得到屏幕寬度sh = root.winfo_screenheight()#得到屏幕高度ww = 500wh = 300x = (sw-ww) / 2y = (sh-wh) / 2-50root.geometry('%dx%d+%d+%d' %(ww,wh,x,y))# root.iconbitmap(’tb.ico’)lb2=Label(root,text='輸入內(nèi)容,按回車鍵分析')lb2.place(relx=0, rely=0.05)txt = Text(root,font=('宋體',20))txt.place(rely=0.7, relheight=0.3,relwidth=1)inp1 = Text(root, height=15, width=65,font=('宋體',18))inp1.place(relx=0, rely=0.2, relwidth=1, relheight=0.4)def run1(): txt.delete('0.0',END) a = inp1.get(’0.0’,(END)) p=core(a) s=p.main() print(s) txt.insert(END, s) # 追加顯示運(yùn)算結(jié)果def button1(event): btn1 = Button(root, text=’分析’, font=('',12),command=run1) #鼠標(biāo)響應(yīng) btn1.place(relx=0.35, rely=0.6, relwidth=0.15, relheight=0.1) # inp1.bind('<Return>',run2) #鍵盤響應(yīng)button1(1)root.mainloop()
運(yùn)行一下:

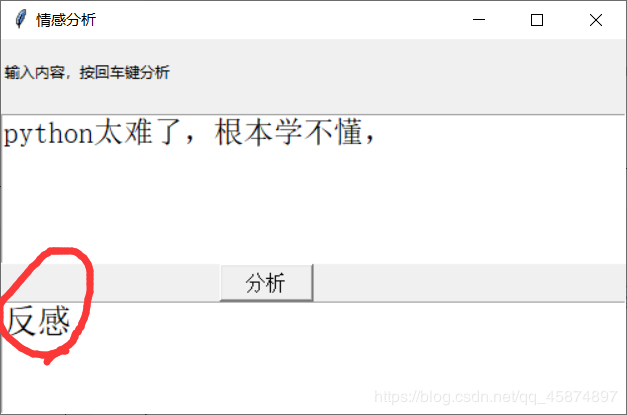
項(xiàng)目已經(jīng)完成了,簡(jiǎn)單的實(shí)現(xiàn)了一下情感分析,不過(guò)泛化能力一般般,輸入的文本風(fēng)格類似與網(wǎng)上購(gòu)物的評(píng)論那樣才看起來(lái)有點(diǎn)準(zhǔn)確,比如喜歡,討厭,好,不好,質(zhì)量,態(tài)度這些網(wǎng)店評(píng)論經(jīng)常出現(xiàn)的詞匯分析起來(lái)會(huì)很準(zhǔn),但是例如溫柔,善良,平易近人這些詞匯分析的就會(huì)很差。優(yōu)化的話我感覺可以訓(xùn)練各種風(fēng)格的樣本,或集成學(xué)習(xí)多個(gè)學(xué)習(xí)器進(jìn)行分類,方法很多,但是實(shí)現(xiàn)起來(lái)又是一個(gè)大工程,像我這最后一排的學(xué)生,還是去打游戲去咯。
項(xiàng)目中的訓(xùn)練樣本,訓(xùn)練好的模型以及完整項(xiàng)目代碼↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
http://xiazai.jb51.net/202007/yuanma/data_jb51.rar
到此這篇關(guān)于python使用Word2Vec進(jìn)行情感分析解析的文章就介紹到這了,更多相關(guān)python Word2Vec 情感分析 內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 用xslt+css讓RSS顯示的跟網(wǎng)頁(yè)一樣漂亮2. 利用CSS制作3D動(dòng)畫3. 使用Spry輕松將XML數(shù)據(jù)顯示到HTML頁(yè)的方法4. 存儲(chǔ)于xml中需要的HTML轉(zhuǎn)義代碼5. HTML5 Canvas繪制圖形從入門到精通6. 讓chatgpt將html中的圖片轉(zhuǎn)為base64方法示例7. CSS3實(shí)現(xiàn)動(dòng)態(tài)翻牌效果 仿百度貼吧3D翻牌一次動(dòng)畫特效8. 《CSS3實(shí)戰(zhàn)》筆記--漸變?cè)O(shè)計(jì)(一)9. html5手機(jī)觸屏touch事件介紹10. 讀大數(shù)據(jù)量的XML文件的讀取問(wèn)題
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備