python使用requests庫爬取拉勾網招聘信息的實現
按F12打開開發者工具抓包,可以定位到招聘信息的接口
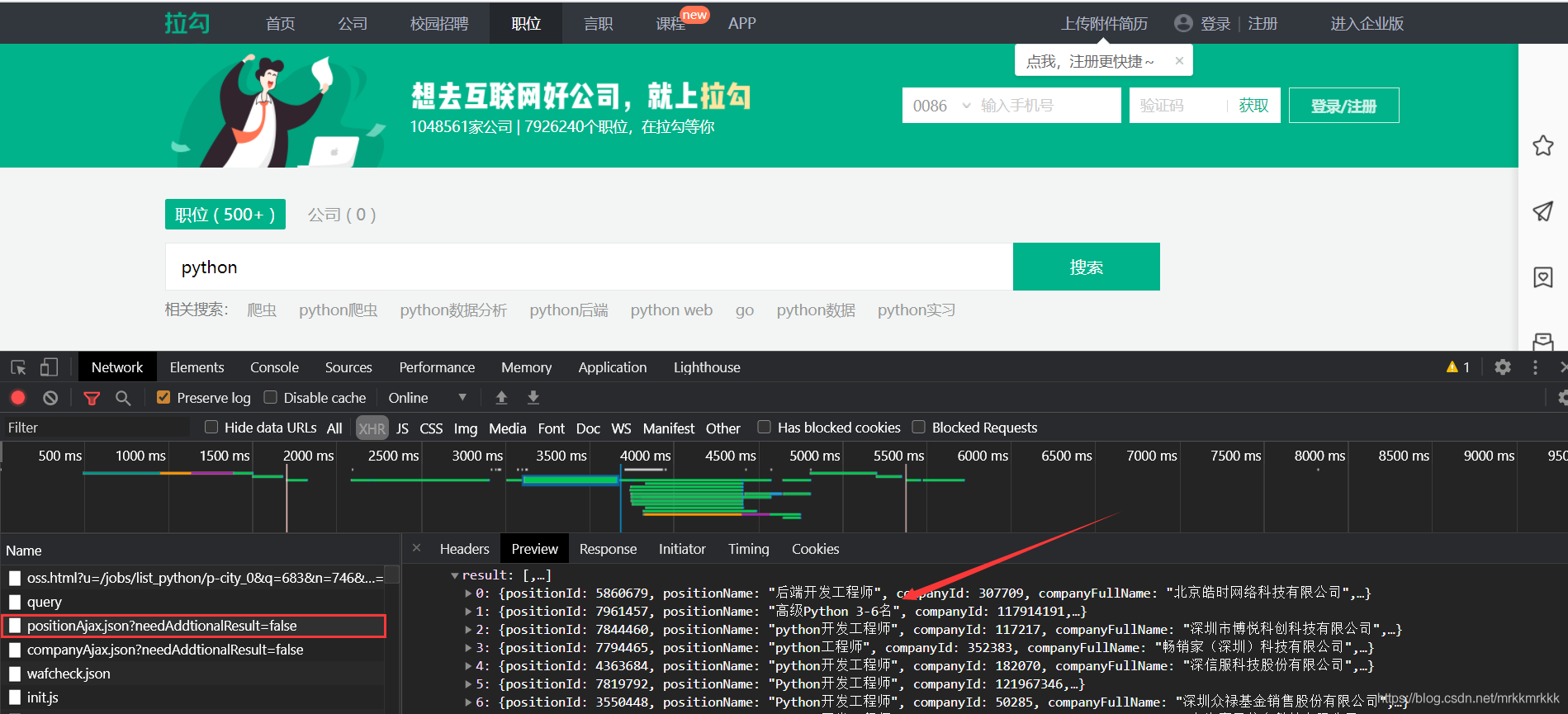
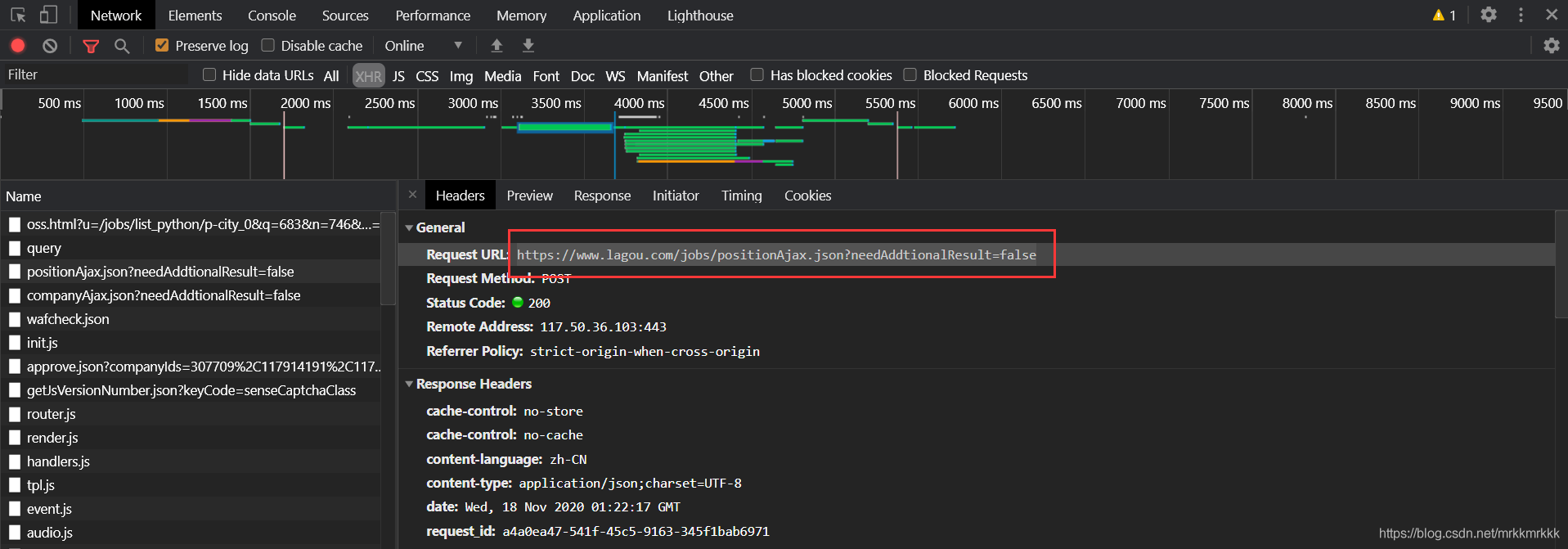
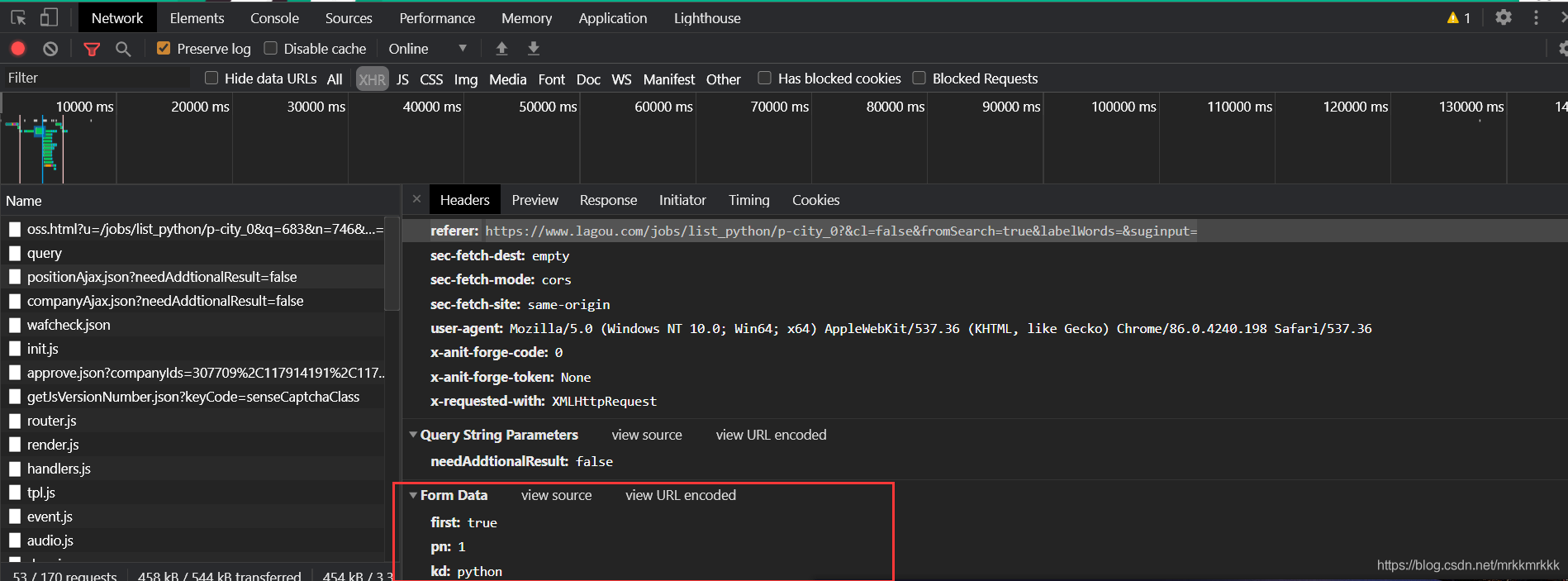
在請求中可以獲取到接口的url和formdata,表單中pn為請求的頁數,kd為關請求職位的關鍵字
使用python構建post請求
data = { ’first’: ’true’, ’pn’: ’1’, ’kd’: ’python’}headers = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}res = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data,headers=headers)print(res.text)
發現沒有從接口獲取到數據

換了個網絡后接口還是會返回操作頻繁的錯誤信息,仔細檢查后發現這個接口需要一個動態的cookies不然會一值返回錯誤頻繁
data = { ’first’: ’true’, ’pn’: ’1’, ’kd’: ’python’}#頭部中必須有user-agent和referer不然不會返回cookiesheaders = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}#通過訪問主頁獲取cookiesr1= requests.get('https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’',headers=headers)#再post請求中傳入cookiesr2 = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data,headers=headers, cookies=r2.cookies)print(r2.text)
注意!每請求十次接口cookies也會刷新一次,下面貼上完整爬蟲代碼
import jsonimport loggingimport requests#獲取cookiedef getCookie(): res = requests.get('https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',headers=headers) return res.cookies#獲取json數據def getPage(i, cookies, kw): data = { ’first’: ’true’, ’pn’: i, ’kd’: kw } res = requests.post('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data, headers=headers, cookies=cookies) return json.loads(res.text)#合并列表def reduceList(l): text = '' for i in l: text += i + ' ' return text.strip()#提取字段并保存到文件中def saveInCsv(f, data): js = data['content']['positionResult']['result'] for node in js: # 對空值進行處理 district = node['district'] if district != None: district = '-' + district else: district = '' f.write( node['positionName'] + '·' + node['city'] + district + '·' + node['salary'] + '·' + node['workYear'] + '·' + node['education'] + '·' + reduceList(node['skillLables']) + '·' + node['companyShortName'] + '·' + node['companySize'] + '·' + node['positionAdvantage'] + 'n')if __name__ == ’__main__’: #定義頭部 headers = { ’referer’: ’https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=’, ’user-agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’ } #初始化cookie cookies = getCookie() with open('file.csv', 'w', encoding='utf-8') as f: for i in range(1, 31): #每十個請求重新獲取cookie if (i % 10 == 0):cookies = getCookie() #解析字段并存儲 data = getPage(i, cookies, 'python') saveInCsv(f, data)
到此這篇關于python使用requests庫爬取拉勾網招聘信息的實現的文章就介紹到這了,更多相關python requests爬取拉勾網內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備