Python lxml庫的簡單介紹及基本使用講解
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的數(shù)據(jù);lxml和正則一樣,也是用C語言實現(xiàn)的,是一款高性能的python HTML、XML解析器,也可以利用XPath語法,來定位特定的元素及節(jié)點信息
HTML是超文本標記語言,主要用于顯示數(shù)據(jù),他的焦點是數(shù)據(jù)的外觀XML是可擴展標記語言,主要用于傳輸和存儲數(shù)據(jù),他的焦點是數(shù)據(jù)的內(nèi)容
2.安裝lxml方法方法1:在cmd運行窗口中輸入:pip install lxml
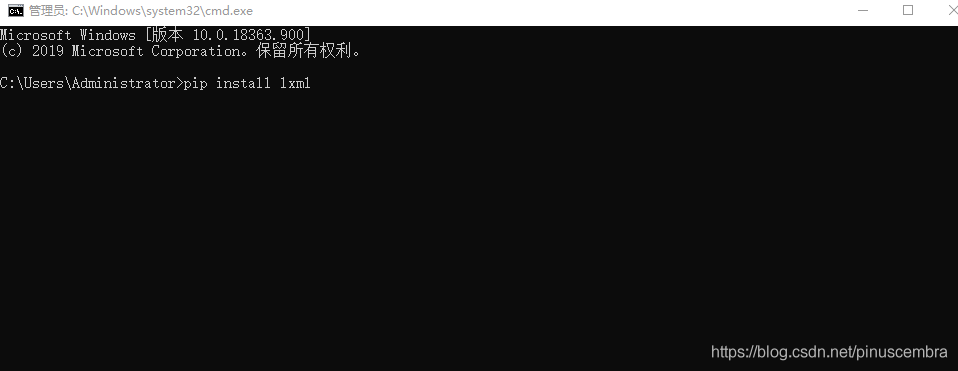
方法2:在Pycharm中下載File?Setting?Project?Project Interpreter?點擊右上角的“+”—第1步
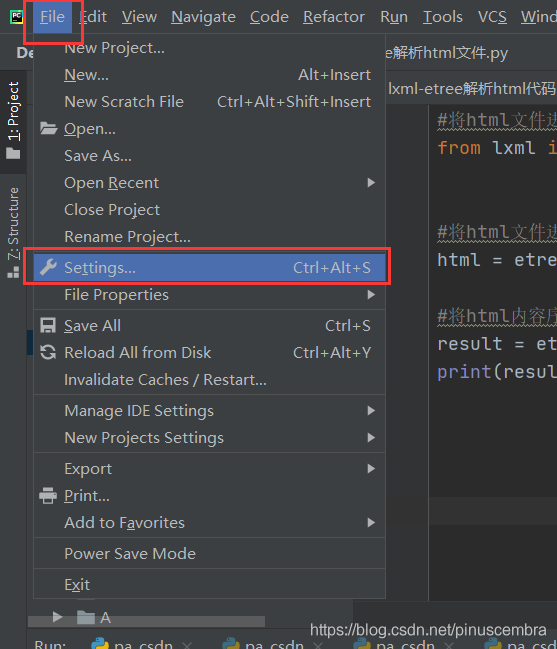
第2步
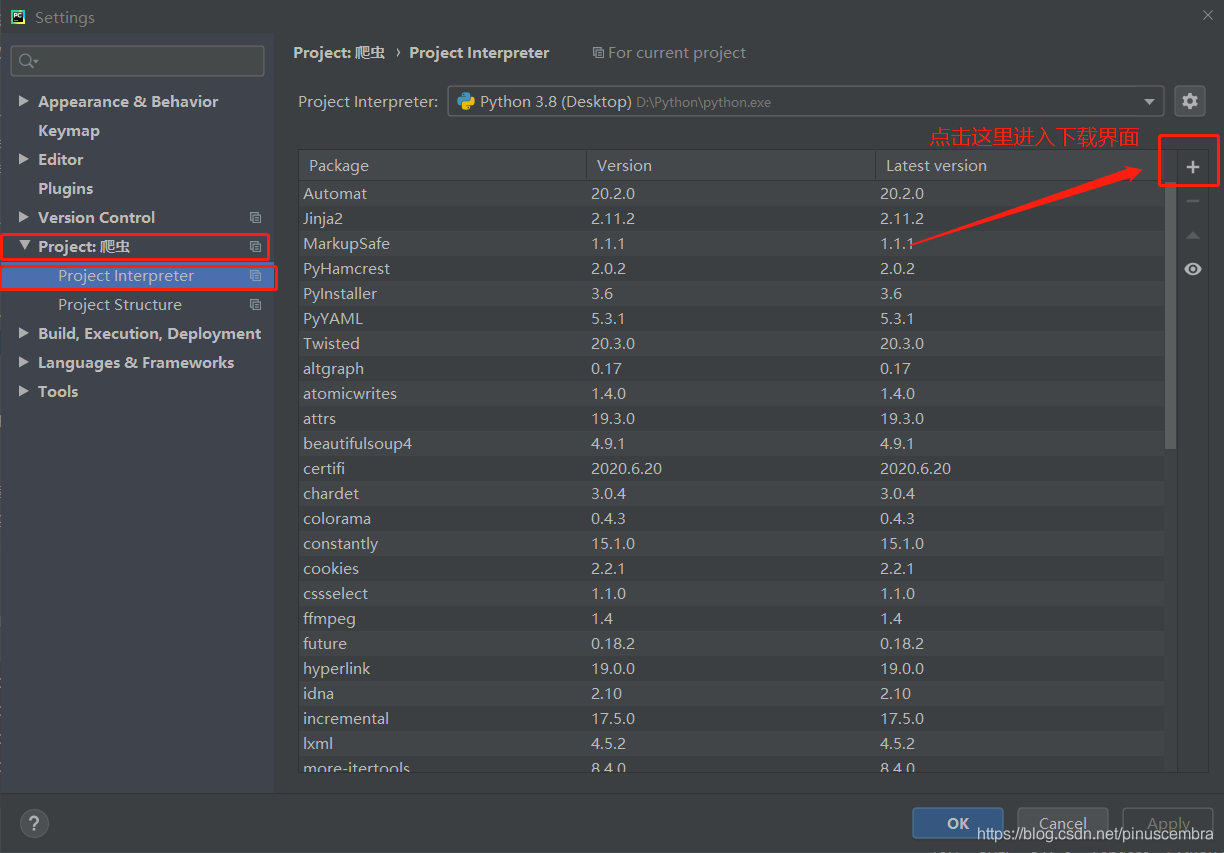
第3步
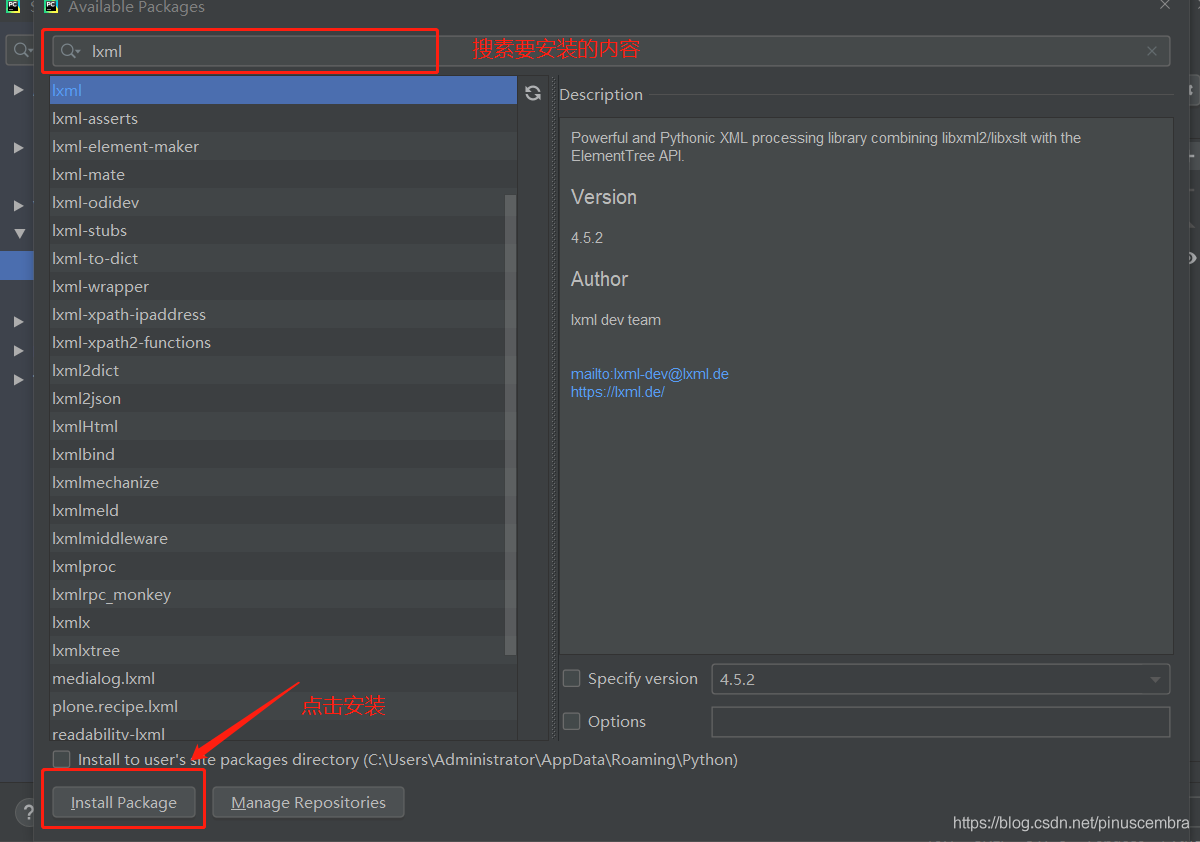
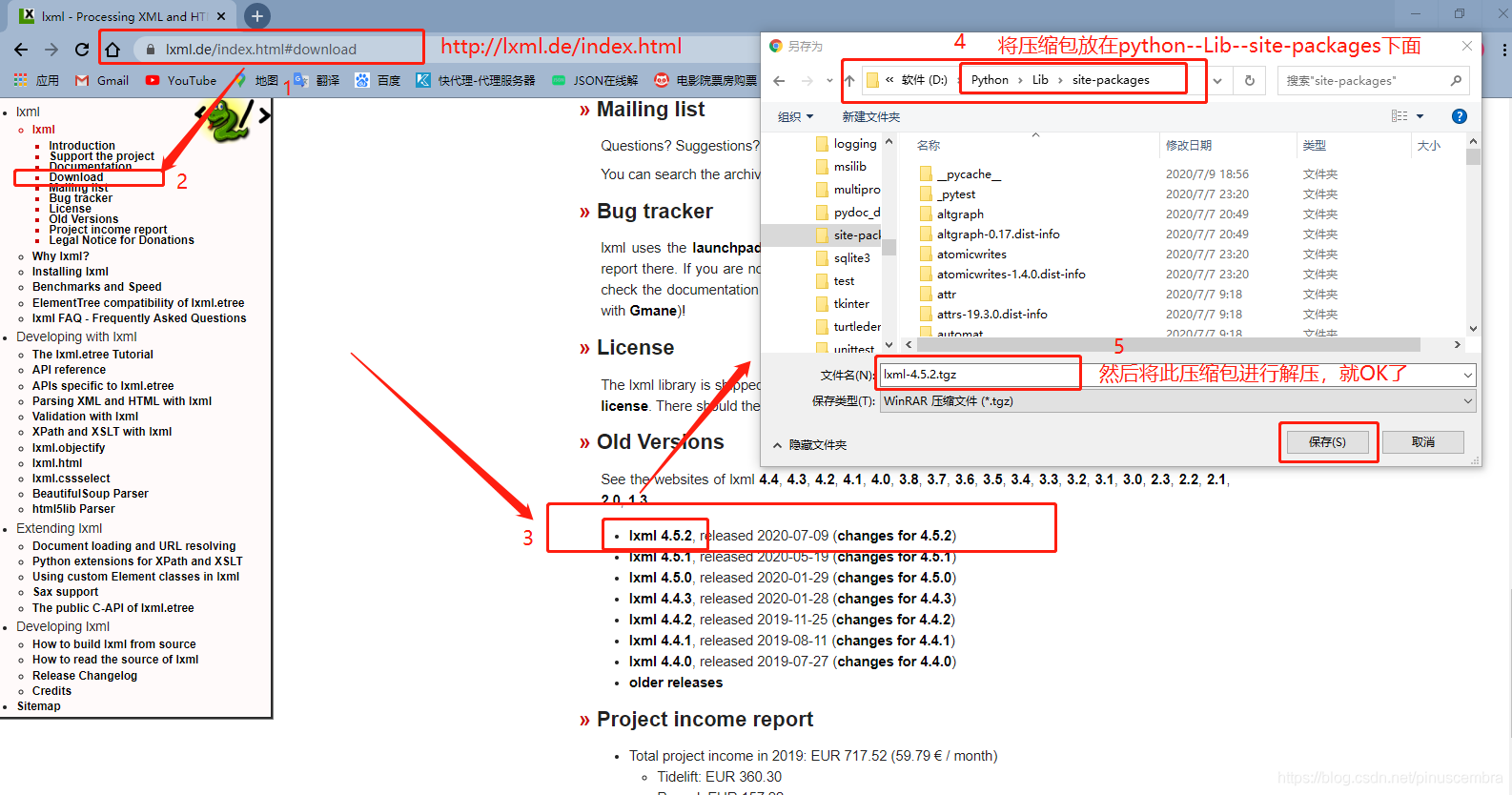
方法3:進入這個網(wǎng)站進行下載:https://lxml.de/index.html
我們可以利用他解析HTML代碼,并且在解析HTML代碼的時候,如果HTML代碼不規(guī)范或者不完整,lxml解析器會自動修復(fù)或補全代碼,從而提高效率
實例1:解析HTML代碼塊
#提取html中的數(shù)據(jù)from lxml import etreetext = ’’’<html> <div class='clearfix'> <div class='nav_com'> <ul> <li class='active'><a href='http://www.cgvv.com.cn/' rel='external nofollow' >推薦</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/python' rel='external nofollow' >Python</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/java' rel='external nofollow' >Java</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/web' rel='external nofollow' >前端</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/arch' rel='external nofollow' >架構(gòu)</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/db' rel='external nofollow' >數(shù)據(jù)庫</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/5g' rel='external nofollow' >5G</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/game' rel='external nofollow' >游戲開發(fā)</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/mobile' rel='external nofollow' >移動開發(fā)</a></li> <li class=''><a href='http://www.cgvv.com.cn/nav/ops' rel='external nofollow' >運維</a></li> </ul> </div> </div></html>></html>>’’’#將字符串解析為html文檔html = etree.HTML(text)#print(html)#將字符串序列化為htmlresult = etree.tostring(html).decode(’utf-8’)print(result)
實例2:讀取并解析html文件
#將html文件進行解析from lxml import etree#將html文件進行讀取html = etree.parse(’data.html’)#將html內(nèi)容序列化result = etree.tostring(html).decode(’utf-8’)print(result)
到此這篇關(guān)于Python lxml庫的簡單介紹及基本使用講解的文章就介紹到這了,更多相關(guān)Python lxml庫使用內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 以PHP代碼為實例詳解RabbitMQ消息隊列中間件的6種模式2. html小技巧之td,div標簽里內(nèi)容不換行3. PHP字符串前后字符或空格刪除方法介紹4. 將properties文件的配置設(shè)置為整個Web應(yīng)用的全局變量實現(xiàn)方法5. nestjs實現(xiàn)圖形校驗和單點登錄的示例代碼6. AspNetCore&MassTransit Courier實現(xiàn)分布式事務(wù)的詳細過程7. XML入門的常見問題(一)8. jsp cookie+session實現(xiàn)簡易自動登錄9. css進階學習 選擇符10. Echarts通過dataset數(shù)據(jù)集實現(xiàn)創(chuàng)建單軸散點圖

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備