python+selenium爬取微博熱搜存入Mysql的實(shí)現(xiàn)方法
最終的效果
廢話不多少,直接上圖
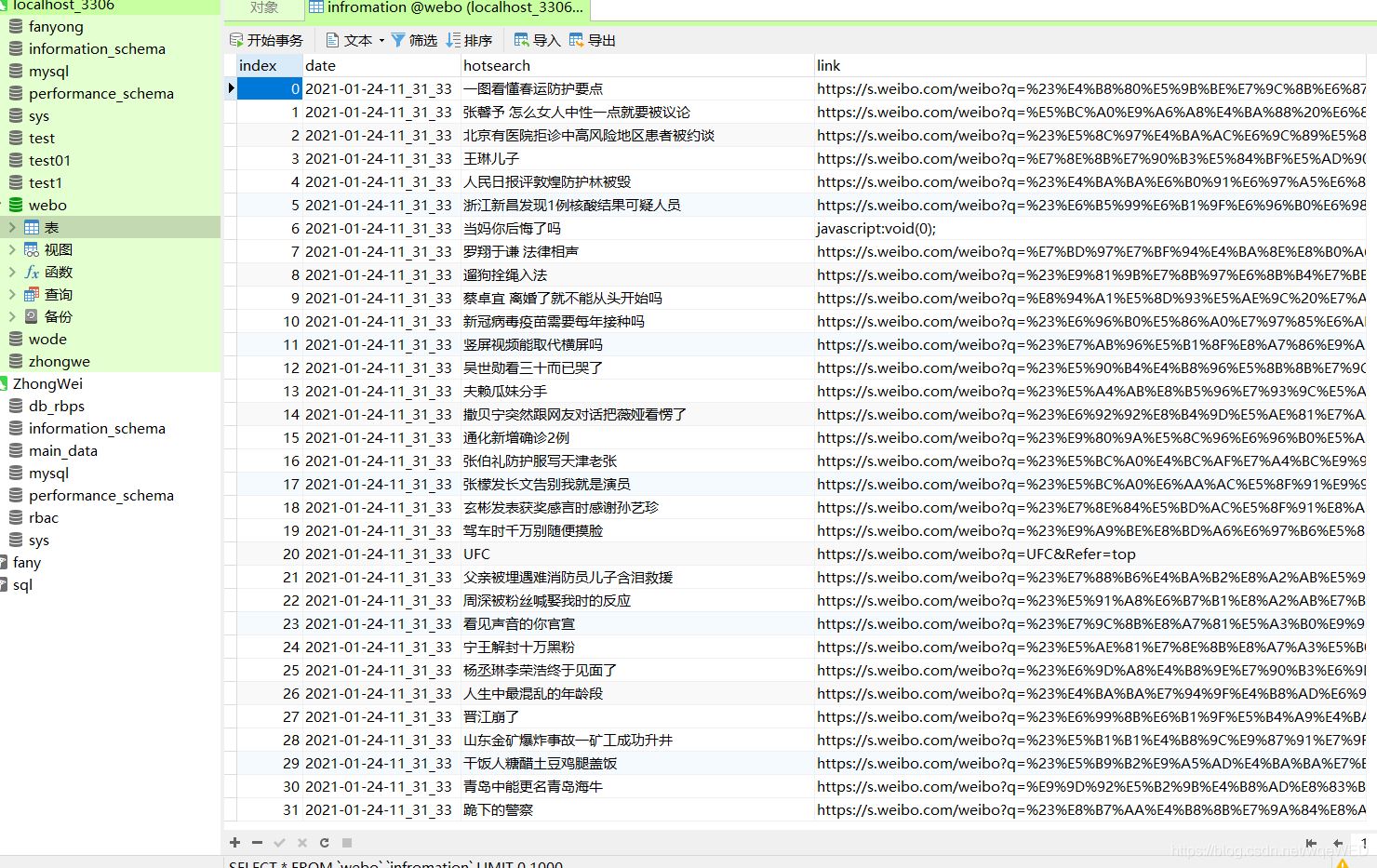
這里可以清楚的看到,數(shù)據(jù)庫里包含了日期,內(nèi)容,和網(wǎng)站link下面我們來分析怎么實(shí)現(xiàn)
使用的庫import requestsfrom selenium.webdriver import Chrome, ChromeOptionsimport timefrom sqlalchemy import create_engineimport pandas as pd
目標(biāo)分析
這是微博熱搜的link:點(diǎn)我可以到目標(biāo)網(wǎng)頁

首先我們使用selenium對(duì)目標(biāo)網(wǎng)頁進(jìn)行請求然后我們使用xpath對(duì)網(wǎng)頁元素進(jìn)行定位,遍歷獲得所有數(shù)據(jù)然后使用pandas生成一個(gè)Dataframe對(duì)像,直接存入數(shù)據(jù)庫
一:得到數(shù)據(jù)
我們看到,使用xpath可以得到51條數(shù)據(jù),這就是各熱搜,從中我們可以拿到鏈接和標(biāo)題內(nèi)容
all = browser.find_elements_by_xpath(’//*[@id='pl_top_realtimehot']/table/tbody/tr/td[2]/a’) #得到所有數(shù)據(jù)context = [i.text for i in c] # 得到標(biāo)題內(nèi)容 links = [i.get_attribute(’href’) for i in c] # 得到link
然后我們再使用zip函數(shù),將date,context,links合并zip函數(shù)是將幾個(gè)列表合成一個(gè)列表,并且按index對(duì)分列表的數(shù)據(jù)合并成一個(gè)元組,這個(gè)可以生產(chǎn)pandas對(duì)象。
dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=[’date’, ’hotsearch’, ’link’])
其中date可以使用time模塊獲得
二:鏈接數(shù)據(jù)庫這個(gè)很容易
enging = create_engine('mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8')pdf.to_sql(name=’infromation’, con=enging, if_exists='append')
總代碼
from selenium.webdriver import Chrome, ChromeOptionsimport timefrom sqlalchemy import create_engineimport pandas as pddef get_data(): url = r'https://s.weibo.com/top/summary' # 微博的地址 option = ChromeOptions() option.add_argument(’--headless’) option.add_argument('--no-sandbox') browser = Chrome(options=option) browser.get(url) all = browser.find_elements_by_xpath(’//*[@id='pl_top_realtimehot']/table/tbody/tr/td[2]/a’) context = [i.text for i in all] links = [i.get_attribute(’href’) for i in all] date = time.strftime('%Y-%m-%d-%H_%M_%S', time.localtime()) dates = [] for i in range(len(context)): dates.append(date) # print(len(dates),len(context),dates,context) dc = zip(dates, context, links) pdf = pd.DataFrame(dc, columns=[’date’, ’hotsearch’, ’link’]) # pdf.to_sql(name=in, con=enging, if_exists='append') return pdfdef w_mysql(pdf): try: enging = create_engine('mysql+pymysql://root:123456@localhost:3306/webo?charset=utf8') pdf.to_sql(name=’infromation’, con=enging, if_exists='append') except: print(’出錯(cuò)了’)if __name__ == ’__main__’: xx = get_data() w_mysql(xx)
到此這篇關(guān)于python+selenium爬取微博熱搜存入Mysql的實(shí)現(xiàn)方法的文章就介紹到這了,更多相關(guān)python selenium爬取微博熱搜存入Mysql內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python實(shí)現(xiàn)讀取類別頻數(shù)數(shù)據(jù)畫水平條形圖案例2. ASP中格式化時(shí)間短日期補(bǔ)0變兩位長日期的方法3. html小技巧之td,div標(biāo)簽里內(nèi)容不換行4. 利用CSS3新特性創(chuàng)建透明邊框三角5. ASP腳本組件實(shí)現(xiàn)服務(wù)器重啟6. ASP刪除img標(biāo)簽的style屬性只保留src的正則函數(shù)7. WML語言的基本情況8. asp讀取xml文件和記數(shù)9. 詳解盒子端CSS動(dòng)畫性能提升10. XHTML 1.0:標(biāo)記新的開端
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備