Python爬蟲的亂碼問題?
問題描述
使用python實(shí)現(xiàn)模擬登陸并爬取返回頁面的時(shí)候出現(xiàn)了亂碼,目標(biāo)網(wǎng)頁的編碼使用utf-8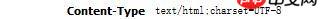
相關(guān)代碼:
#coding=utf-8import urllibimport urllib2headers={ ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’, ’Accept-Encoding’:’gzip, deflate’, ’Accept-Language’:’zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’, ’Connection’:’keep-alive’, ’User-Agent’:’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.73 Safari/537.36’}payload={ ’_eventId’:’submit’, ’lt’:’_cF2A0EB3F-D044-046C-6F4A-C828DE0ACE8E_k8B4BE5F5-4CAD-375D-0DDC-FB84A18445DF’, ’password’:’’, ’submit’:’登 錄’, ’username’:’’}payload=urllib.urlencode(payload)request = urllib2.Request(posturl, payload, headers)print requestresponse = urllib2.urlopen(request)text = response.read()print text
控制臺(tái)輸出信息:
第一次遇見這種亂碼比較懵逼
問題解答
回答1:urllib2沒有處理壓縮的問題,你要使用gzip解壓,比如這樣
from StringIO import StringIOimport gzipif response.info().get(’Content-Encoding’) == ’gzip’: buf = StringIO(text) f = gzip.GzipFile(fileobj=buf) data = f.read()
總結(jié)urllib2比較底層,建議使用requests
相關(guān)文章:
1. docker images顯示的鏡像過多,狗眼被亮瞎了,怎么辦?2. 大家好,請(qǐng)問在python腳本中怎么用virtualenv激活指定的環(huán)境?3. 網(wǎng)頁爬蟲 - 用Python3的requests庫模擬登陸B(tài)ilibili總是提示驗(yàn)證碼錯(cuò)誤怎么辦?4. javascript - 關(guān)于audio標(biāo)簽暫停的問題5. android - QQ物聯(lián),視頻通話6. Matlab和Python編程相似嗎,有兩種都學(xué)過的人可以說說嗎7. javascript - 微信小程序封裝定位問題(封裝異步并可能多次請(qǐng)求)8. javascript - Web微信聊天輸入框解決方案9. mysql - 怎么讓 SELECT 1+null 等于 110. 請(qǐng)教各位大佬,瀏覽器點(diǎn) 提交實(shí)例為什么沒有反應(yīng)

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備