爬蟲圖片 - 請教各位:python爬蟲編碼問題,版本3.6,win10 64位下?
問題描述
這是報(bào)錯(cuò)信息:
Traceback (most recent call last): File 'D:pypic_downfrom2255ok.py', line 45, in <module> html = getHtml(url_all[i]) File 'D:pypic_downfrom2255ok.py', line 32, in getHtml html = response.read().decode()UnicodeDecodeError: ’utf-8’ codec can’t decode byte 0xb3 in position 184: invalid start byte
改了好多地方,主要可能是目標(biāo)網(wǎng)站是gb2312編碼,這個(gè)程序在別的網(wǎng)站是可以正常下載圖片的,換上現(xiàn)在的網(wǎng)站就有問題還請各位多多指教,問題出在哪里?試了幾個(gè)方法都不行源碼如下: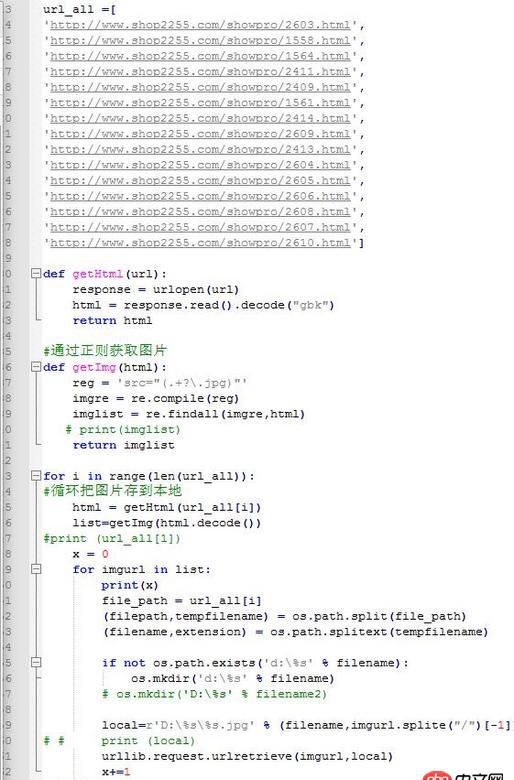
#coding=utf-8import urllib.requestfrom urllib.request import urlopen, urlretrieve import urllibimport urllib.parseimport reimport osfrom bs4 import BeautifulSoupurl_all =[’http://www.shop2255.com/showpro/2603.html’,’http://www.shop2255.com/showpro/1558.html’,’http://www.shop2255.com/showpro/1564.html’,’http://www.shop2255.com/showpro/2411.html’,’http://www.shop2255.com/showpro/2409.html’,’http://www.shop2255.com/showpro/1561.html’,’http://www.shop2255.com/showpro/2414.html’,’http://www.shop2255.com/showpro/2609.html’,’http://www.shop2255.com/showpro/2413.html’,’http://www.shop2255.com/showpro/2604.html’,’http://www.shop2255.com/showpro/2605.html’,’http://www.shop2255.com/showpro/2606.html’,’http://www.shop2255.com/showpro/2608.html’,’http://www.shop2255.com/showpro/2607.html’,’http://www.shop2255.com/showpro/2610.html’]def getHtml(url): response = urlopen(url) html = response.read().decode('gbk') return htmldef getImg(html): reg = ’src='http://www.cgvv.com.cn/wenda/(.+?.jpg)'’ imgre = re.compile(reg) imglist = re.findall(imgre,html) return imglistfor i in range(len(url_all)): html = getHtml(url_all[i]) list=getImg(html.decode()) x = 0 for imgurl in list:print(x)file_path = url_all[i](filepath,tempfilename) = os.path.split(file_path)(filename,extension) = os.path.splitext(tempfilename)if not os.path.exists(’d:%s’ % filename): os.mkdir(’d:%s’ % filename)# os.mkdir(’D:%s’ % filename2)local=r’D:%s%s.jpg’ % (filename,imgurl.splite('/')[-1])urllib.request.urlretrieve(imgurl,local)x+=1print('done')
問題解答
回答1:# coding: utf-8import urllibimport requestsfrom pyquery import PyQuery as Qimport osbase_url = ’http://www.shop2255.com/’url_all =[’http://www.shop2255.com/showpro/2603.html’]for url in url_all: _, file_name = os.path.split(url) dir_name, _ = os.path.splitext(file_name) if not os.path.exists(dir_name):os.mkdir(dir_name) r = requests.get(url) for _ in Q(r.text).find(’img’):src = Q(_).attr(’src’)image_url = src if src.startswith(’http’) else os.path.join(base_url, src)_, image_name = os.path.split(image_url)image_path = os.path.join(dir_name, image_name)urllib.urlretrieve(image_url, image_path)回答2:
首先在你這個(gè)代碼里面 local=r’D:%s%s.jpg’ % (filename,imgurl.splite('/')[-1])中split寫成了splite.
還有 urllib.request.urlretrieve(imgurl,local)這個(gè)imgurl不是一個(gè)合法的 url,只是一個(gè)相對 url, 要改成絕對 url,需要加上 base_url = ’http://www.shop2255.com/’
還有生成的文件路徑好像也有問題.
# -*- coding: utf-8 -*-import urllib.requestfrom urllib.request import urlopen, urlretrieveimport urllibimport urllib.parseimport reimport osfrom bs4 import BeautifulSoupbase_url = ’http://www.shop2255.com/’url_all =[’http://www.shop2255.com/showpro/2603.html’,’http://www.shop2255.com/showpro/1558.html’,’http://www.shop2255.com/showpro/1564.html’,’http://www.shop2255.com/showpro/2411.html’,’http://www.shop2255.com/showpro/2409.html’,’http://www.shop2255.com/showpro/1561.html’,’http://www.shop2255.com/showpro/2414.html’,’http://www.shop2255.com/showpro/2609.html’,’http://www.shop2255.com/showpro/2413.html’,’http://www.shop2255.com/showpro/2604.html’,’http://www.shop2255.com/showpro/2605.html’,’http://www.shop2255.com/showpro/2606.html’,’http://www.shop2255.com/showpro/2608.html’,’http://www.shop2255.com/showpro/2607.html’,’http://www.shop2255.com/showpro/2610.html’]def getHtml(url): response = urlopen(url) # print(response.read()) html = response.read().decode('gbk') print(html) return htmldef getImg(html): reg = ’src='http://www.cgvv.com.cn/wenda/(.+?.jpg)'’ imgre = re.compile(reg) imglist = re.findall(imgre, html) return imglistfor i in range(len(url_all)): html = getHtml(url_all[i]) # 注意: 我這里沒有你那個(gè)錯(cuò)誤,我只需要改這個(gè)就行了 # list = getImg(html.decode()) list = getImg(html) # print(list) x = 0 for imgurl in list:print(x)file_path = url_all[i](filepath, tempfilename) = os.path.split(file_path)(filename, extension) = os.path.splitext(tempfilename)if not os.path.exists(’d:%s’ % filename): os.mkdir(’d:%s’ % filename)# os.mkdir(’D:%s’ % filename2)local = r’D:%s%s.jpg’ % (filename, imgurl.split('/')[-1])try: urllib.request.urlretrieve(base_url + imgurl, local)except: print('can’t retrieve the' + base_url + imgurl)x += 1print('done')
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備